NIMBY Rails devblog 2021-08
Private train track pathfinding
When some part of the game (the train AI, the line system, the UI, etc.) needs to find a track path from point A to point B over your line network, it uses the track pathfinder. On a first look this appears to be a process with little variety, always existing some optimal path from A to B, which the pathfinder (hopefully) is capable of finding. But in reality it all depends on what is the definition of optimal. Before v1.2 there was only one definition of optimal: the shortest path, as in distance over the tracks.
Starting from v1.3 is now possible for different systems of the game to have a different definition of what is an optimal path. And in the case of the train AI, this definition has been made private to every train. This means the train AI, when evaluating a path, will be able to consider things like the train max speed. It is now making decisions based on the combination of the train and track max speed and the time required to roll down the path, as opposed to just the path length.
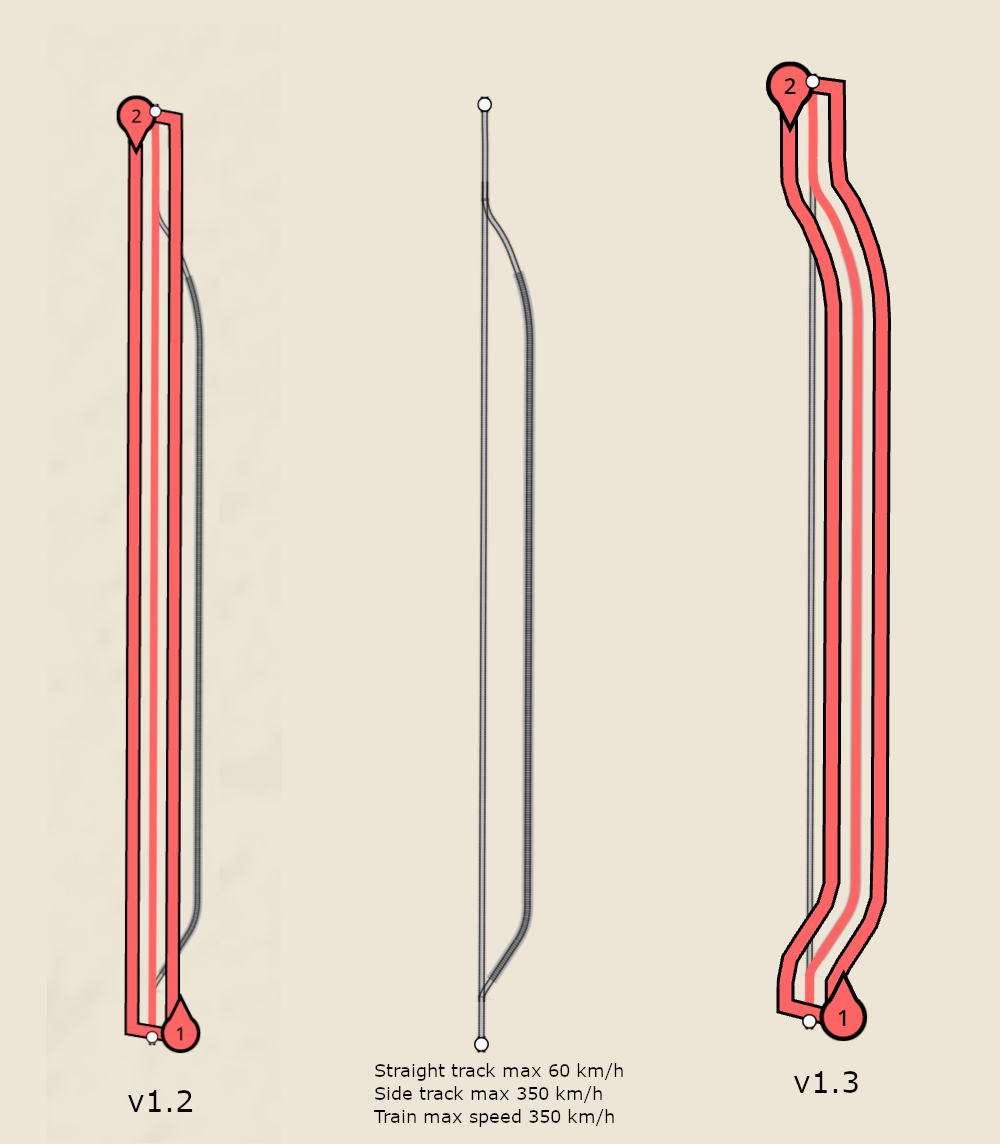
The previous image shows how now trains will be able to find faster, even if longer, track runs, and depending on their capabilities pick the longer but faster track. This can be visualized since the line system is now an user of the train private pathfinder, using its reference train.
The bad side of this new private pathfinding system is that the track pathfind cache becomes useless. Now every individual train is potentially generating unique paths which only apply to itself, so these cannot be shared anymore. To make up for the cache, trains now automatically store the last used path. When they need a new path, a very quick check is performed to see if the new path is actually just a subpath of the old path. This is very often (90%+) the case, since the pathfinder is called at moments like deciding on taking a branch, and the old path already considered it. When the new path is just a subpath of the old one, the pathfinding process is replaced with a very quick “trim path” operation.
This new private pathfinding system, and not depending on the track cache anymore, will make it possible to implement new train and signal features not possible before. For example tag-filtered signals, which flag a color based on the train or line tags.
New map backend processing system
The first steps for private pathfinding were made during v1.2 development, but the item itself was too risky for the matured v1.2 cycle, so it was finished just after v1.2 ended. But now it was time to start programming for v1.3. I had already found the datasets I wanted to feature in v1.3, and now a new map processor was required for them. The old processor was never fully designed for the massive tasks it had to tackle, and grew out from some experiments into the massive beast that output the 20GB of game mapping data. Its code is difficult to maintain and understand since I was basically adding things on top on things without any design.
For v1.3 I wanted to start a new processing system, now that I have a clear idea of what I want, both code wise and data wise. For now the new processor only handles raster layers, but it’s precisely these ones that took an inordinate amount of time compared to their complexity in the old code. The new code is fully parallel from the get go, and it’s very focused and succinct, making it easy to maintain and enhance. At some point this new processor will also be able to output vector data, but for now it just had 2 tasks: a new population layer and a new elevation layer.
This new processor is also abandoning the SQLite format in favor of a custom, read only format for storing map data. SQLite is extremely capable, but for storing map data, I’m using less than 1% of its functionality. It’s also optimized for read/write operations, when I only need read operations. The new format is dead simple to generate for the processor and to read for the game, and supports exactly what is required for the game, nothing else.
New population layer
The new population layer replaces the old population system based on finding road nodes and adding them up inside a grid. The new layer is using actual population density data for the entire world, combined with buildup data. The population layer has a resolution of 250m, and the buildup data is 30m. The game combines both of them to create a single layer:
Storing the 250m layer was straightforward, with a small footprint given the relative sparseness of population vs land, and it now being super high resolution. But the 30m was more interesting, since stored as-is would have required 4GB+. In the end I realized it can reduced to a single bit per 30m. Combined with some compression this reduced the size to around 200MB. Not bad for a worldwide dataset at 30m! I really like this dataset and I would like at some point to restart my procedural buildings using it as a hint on where to “grow” buildings in the world.
This new population layer finally fixes the population distribution problems of the game caused by the super simple street grid approximation. Now the population is independent of the OSM street density for a given area. Countries like China will see a huge change and become fully playable. This is with v1.2:
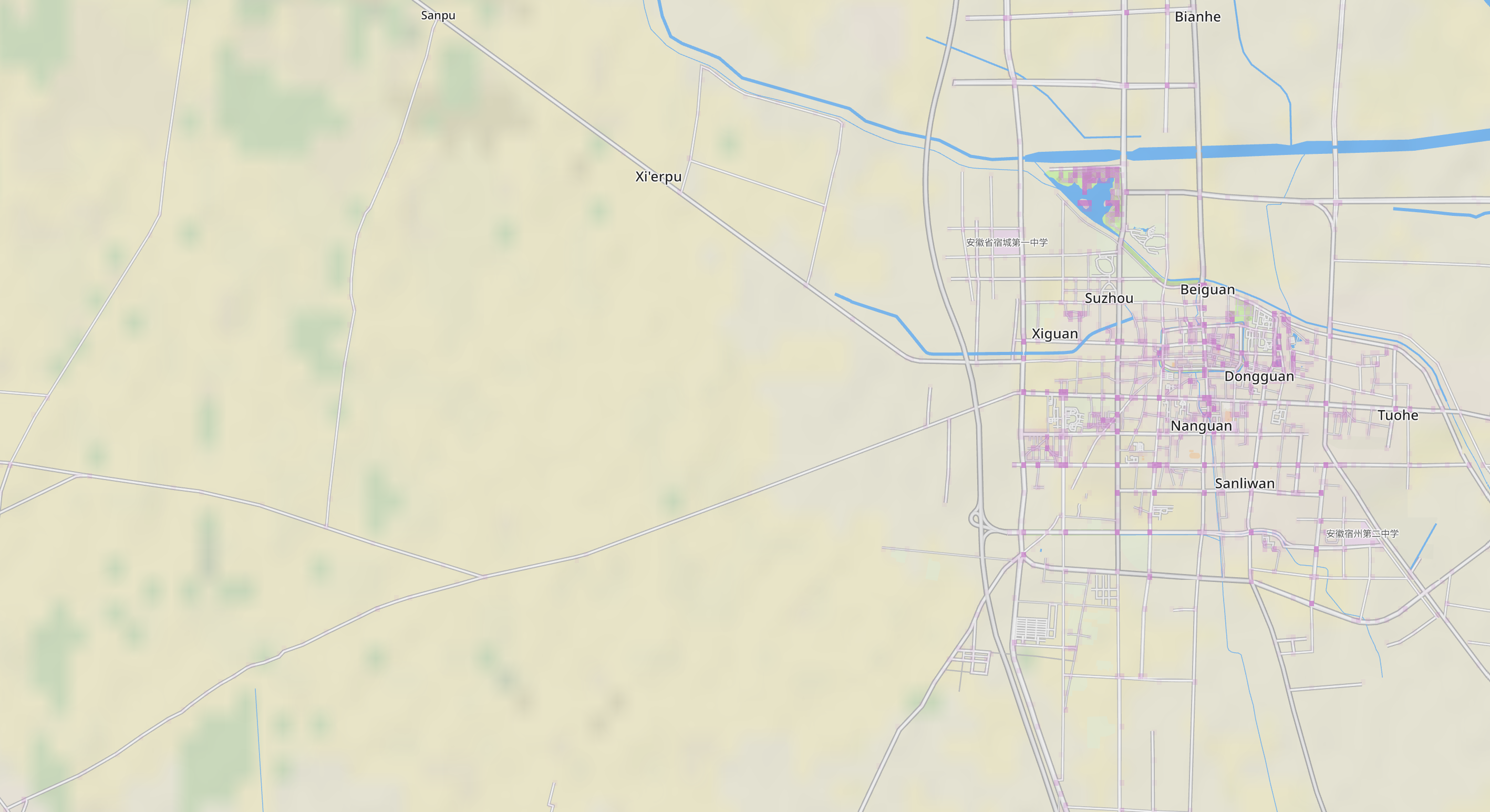
And with v1.3:
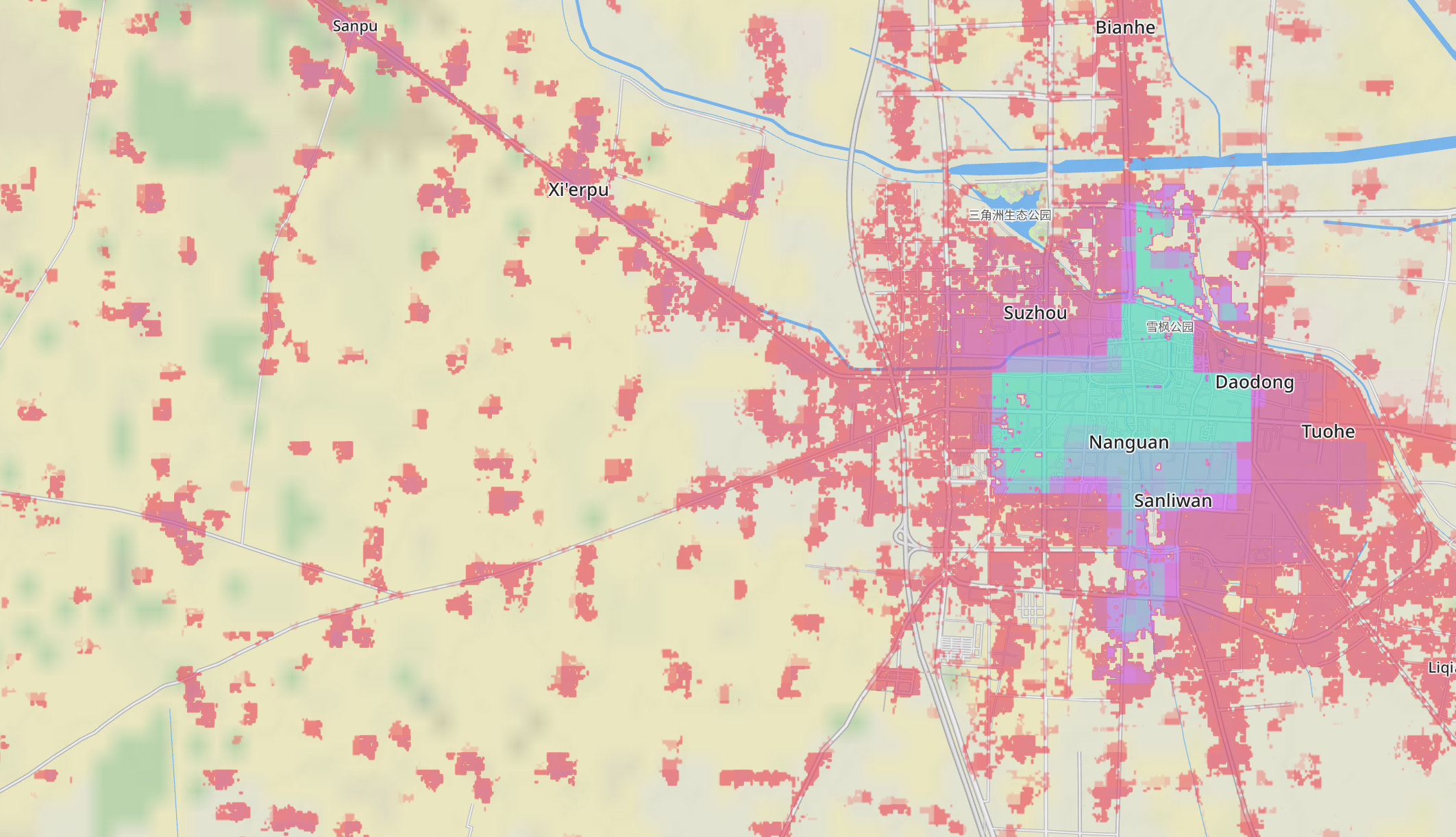
Apart from the obvious much improved coverage, it’s also making less errors. In v1.2 the footpaths in the park near the triangular pond were considered a hot spot of population, while the new layer considers nobody lives there.
New elevation layer
Another dataset I tracked down was a 90m DEM global layer with better coverage than the original DEM layer I was using. This layer will fix the cut out elevation data for high latitudes. With v1.2:
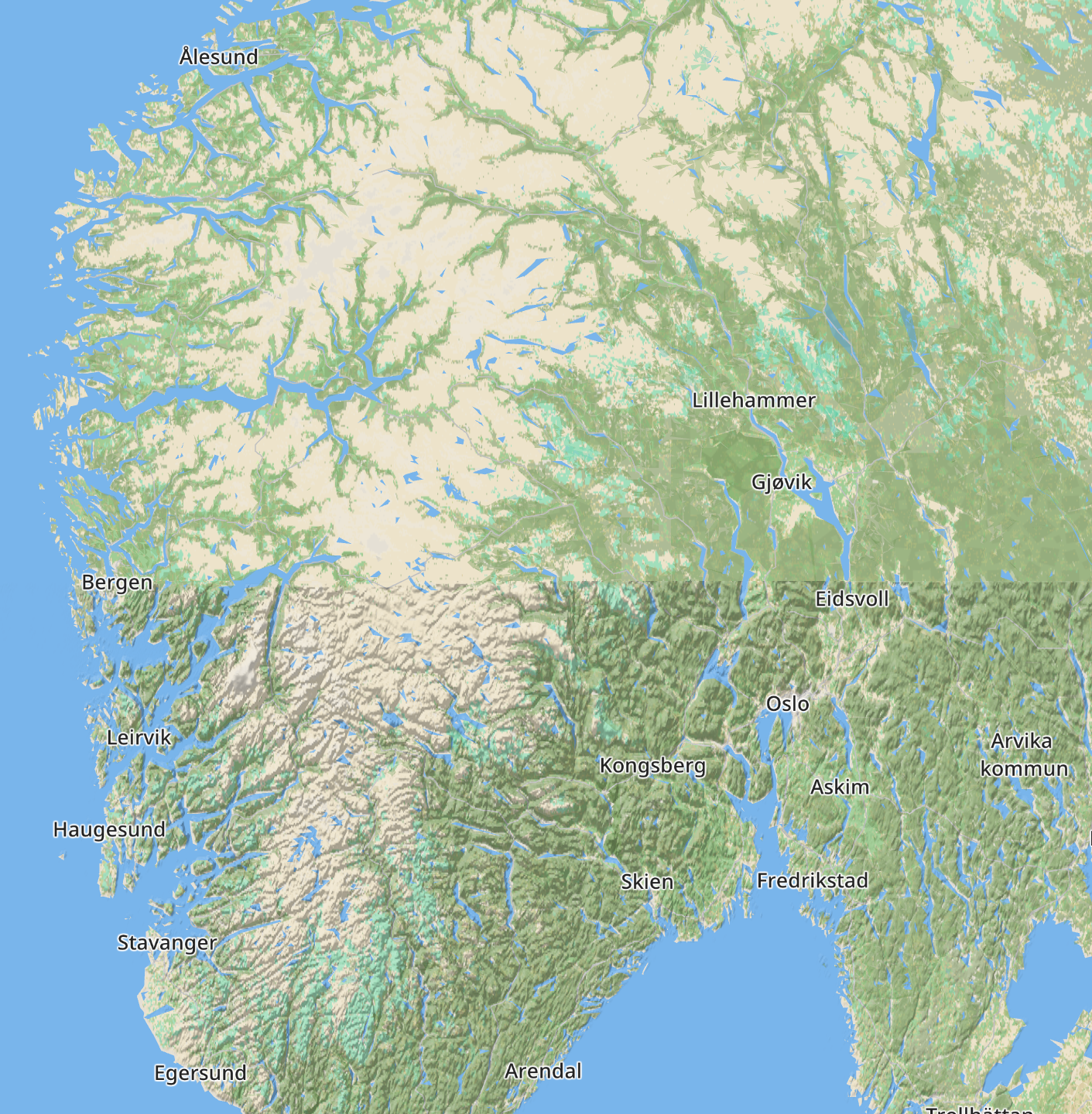
With v1.3:
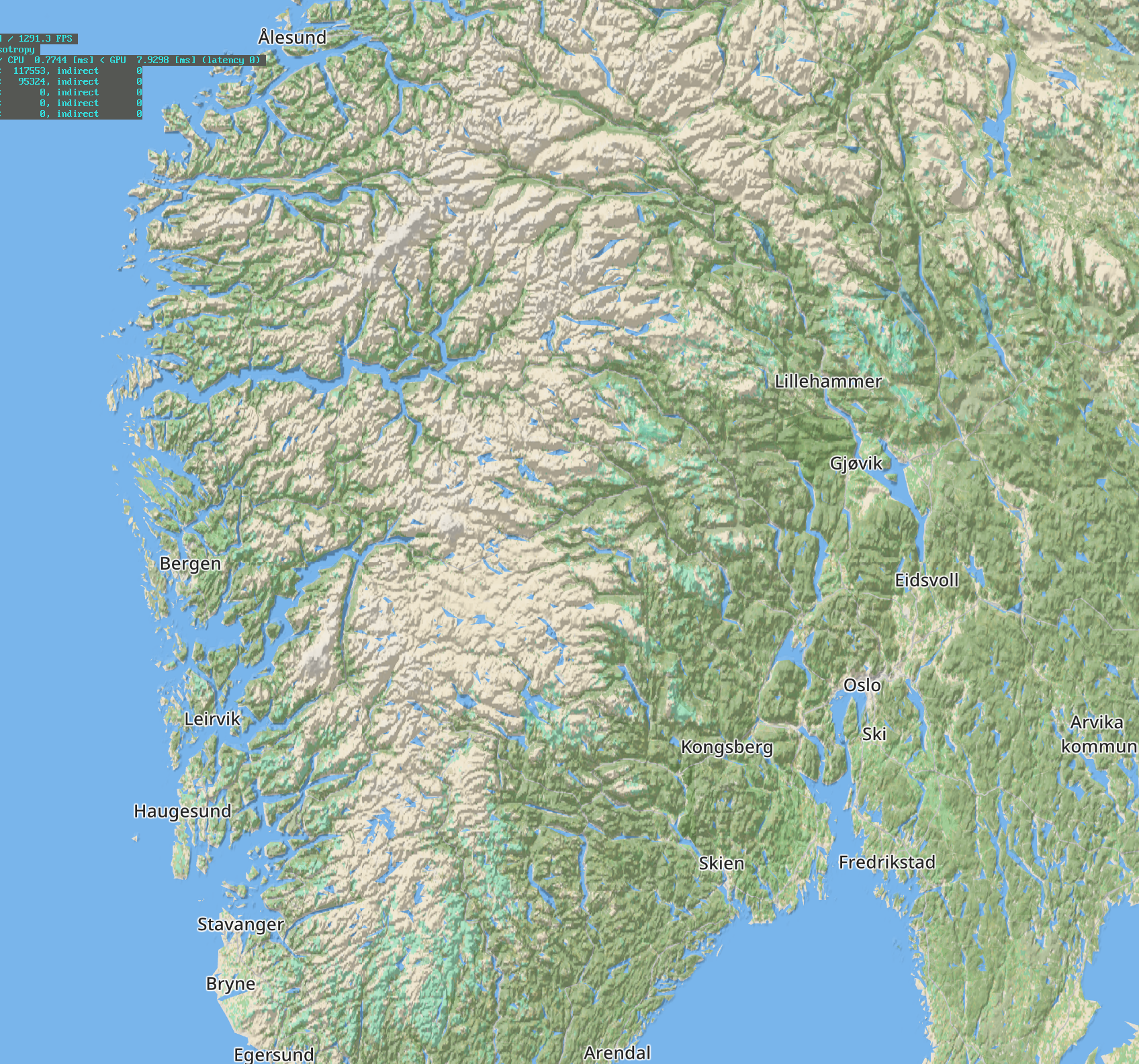
Although the original DEM layer was 30m, the game was downsampling it to 300m for download and disk space considerations. I will try to keep this new layer at 90m and see what compression options I can use for it. But even if I have to downgrade the resolution, it will still be an improvement.