NIMBY Rails devblog 2024-02
End of 1.11 development
The first half of February saw some QoL development in the 1.11 beta branch, in addition to the usual bugfixes. A player favorite: it is now possible to change the start of day for the accounting time.
But the main goal for February was to start the implementation of some new pax generation ideas I have been collecting over the years. At the start of the month I wasn’t sure if it was going to be possible to develop this project as part of the 1.11 beta series or as a whole new version. It eventually became clear it was a much larger effort than anticipated so I decided to release 1.11.14 beta as the default version and move on to 1.12. The rest of this post is about 1.12 private development.
Establishing a maximalist goal to guide pax demand v2 development: worldwide, unbiased demand based on pax density
Let’s unpack the title of this section.
- Maximalist goal: since the idea is to guide the design and development, a (likely to be unfeasible) goal is set
- Pax demand v2: the project to replace the current in-game systems of pax demand curves based on time and distance, pax generation rate at origin stations, and picking destination stations for these paxs, for a new set of systems which try to solve documented issues and improve the simulation quality
- Worldwide: this idealized goal is formulated ignoring the existence of origin stations; it assumes the entire world is generating paxs at every possible point with more than 0 population
- Unbiased: also, this idealized goal is formulated ignoring the existence of destination stations; it assumes every other point in the world with nonzero population is a valid destination
- Based on pax density: the pax density as shown in the pax population layer should dictate what are the origin and destinations points for pax trips. Not the stations, not the service frequency, not the station capacities, not the catch areas.
Note that this goal is leaving out of the design many ideas: time of day demand curves, POIs, distance preference for destinations, etc. This is on purpose and it is only at this stage of the design. These factors can and will be introduced progressively, and some already are later in this post.
As mentioned earlier it should be clear this design goal is useless by itself. It only exists to try to find a system to model the existence of a point in the world containing one pax who wants to travel to a different point, solely based on population density. The experimental journey to that goal is the objective, and from that journey new things can be learned to design the real v2 pax demand model.
Unbiased origin picking based on pax density
To scope this step of the experiment is to find points of origin for pax trips, and only for the origin. The map data in NIMBY Rails is organized in multi resolution tiles, but for the purposes of this first step only the max resolution level will be considered. This level has a 320x320 resolution texture per tile for the combined building and pax layer, for around 15m per pixel at the equator. The goal is to find random positions in this population tile, with more frequently picking positions with higher population (I will explain later how this scales to a worldwide goal). Additionally positions with zero population should never be picked. Absent in this goal is establishing a rate of pax generation per second. This aspect will be controlled by a separate part of the system.
To get a feeling of the data I first started doing some histograms of the “size” of the texels. This is just declaring some bucket ranges and adding up the texels of the texture.
Remember this is just bucketing for texel “sizes”, it’s not adding population. This visualization shows some nice and kinda expected normal distributed shapes. But it is also kinda useless for the purpose of pax picking. For that purpose the actual pax per texel needs to be considered.
This visualization is now showing every texel in the texture as its own independent bar, the higher the more population in the texel, sorted by more pax to less pax. Then it is averaged by 320 so it fits as a graph in the tile. This is still not directly useful but at least it is now visualizing the correct object.
Cumulative distribution functions (CDF) are used in statistics to model the probability of a random variable being lower than certain value. In the case of game pax tiles, the variable is the amount of pax in a position of the tile. The texture is not a continuos function, it is a discrete collection of points. CDFs are possible for such collections, and in fact are universally used for basically anything that requires random picking from a large collection of objects, each with their own probability. In our case these objects are the individual texels of the texture, and the probability attached to each one is determined by (amount of pax in the texel) / (sum of pax in the texture). The discrete CDF is then just adding up these values in order, for any order.
This is how the CDF version of the previous screenshot looks like:
But we are not interested in texels with 0 population, so let’s fix that:
And this is now an usable discrete CDF “function”. Each value represents the population of a texel in the population texture, divided by the total population (this is its probability), plus the accumulated probability up to that point. That’s why it always sums up to 1. To use it, since its values are always strictly increasing due to the sum, we can use a binary search. Basically we invoke an uniform random number generator to return a value between 0 and 1, and then lookup that number in the CDF by using a binary search. It won’t be an exact match, so we take the lowest bound next to it. This corresponds to a position in the tile, and thus it becomes a possible pax spawn point:
The video shows this method being used to generate pax spawn points. Note how denser population areas generate more spawn points, and how areas with zero population do not generate any.
As a test, I wanted to avoid even doing the binary search. Instead it can be observed the curves of the CDF are usually quite regular. But they are not similar to anything I know (I’m no statistician), so I just used least squares to fit a parabola:

It works but the fitting is not that good. It also needs special handling for the all clipping cases, because they would leave out very important areas of the distribution. To use it we just invert the parabola formula to find the square root for a given Y value, and the resulting X is the corresponding texel position in the texture. It is much faster than the binary search, about 16x. Today’s CPUs are much faster at maths than they are at memory access, so a single square root is nothing compared to the 15 memory access required for the binary search. I am undecided at this point wether to use this optimization; it’s much faster but the clipping cases and the relatively low quality of the curve is not encouraging. I will revisit it in the future.
To scale this technique to the “worldwide” goal, we can just make a CDF for the entire world, representing each max resolution tile as a single population value, its own sum. Then we first pick a tile using this new CDF, and then apply the previous algorithm over the picked texture
Origin picking for actual game usage
How to fit this design as a usable system in the game? To do so we must identify the problems it has for a real time system. The first and main one is requiring access to the full resolution population textures. This means either keeping all of them in RAM (impossible) or loading them on demand from disk.
Fortunately this is easy to solve because, unlike destination picking, there is a way to associate origin picking with player built stations, which still results in unbiased pax generation. The idea is to introduce the concept of “activated” map tiles. This is just a list of map tiles which are covered, at least in part, by the catch area of one or more stations. These are the only tiles the game sim will care about for generating pax. Since even for largest saves it’s a very small subset of the total tiles, the required RAM is relatively small, on the order of 100 MB per 1000 activated tiles, and it could be reduced further with resolution decreases. The ratio between covered tiles and stations varies quite a bit between saves, depending on the building style and goals of the player, but it’s still just a small number. Unlike the map cache, these pax-only tiles will be required to be in RAM 100% of the time, since they are needed on potentially every frame of the simulation for pax generation. A separate trimmed down map tile system will be introduced just for this.
This solves the memory issue, but unless something else is done, it is introducing bias, since not all tiles have the same amount of population. To solve this, each tile will be annotated with its total population sum. From this number a pax generation rate factor can be calculated. This will be an arbitrary formula but in the end it will be just a linear relationship between the amount of pax in a tile and the pax/s generated by the sim for the tile. This will make it possible to process map tiles in the same way stations are processed now: each tile will have a pax flow counter, and on every sim frame it will be incremented by its pax/s flow rate, in turn modulated by (for example) the time of day demand curve.
The end result of this system is zero to N pax generated per tile per sim frame. These pax aren’t just assigned to a tile: with the CDF system, they also have a position inside the tile. This means they can be immediately assigned to a station, using the station catch area. And since they are now geolocated, this opens the door to overlapping catch areas and implementing rules for station selection. A potential problem is that the CDF system can generate pax in positions with zero station coverage. But this is good! It means it’s not biased. I’m not too worried about loss of performance in this case since it will be very fast to generate spawn positions. Plus players naturally build stations on the map areas with the most population, and the CDF will pick these areas most of the time, so very little processing time will be wasted in non serviced spawn positions.
The real hard problem: unbiased picking of destinations
Applying the previous system as-is to pick random destinations would work, but it has problems. For starters it’s obvious that only considering the activated tiles as valid destinations is simultaneously the only feasible way to go, and very unrealistic. It goes against the goal of trying to model a natural demand for going from point A to B independent of what rails and services are built, if at all. But doing it the “correct” way, as if the entire world was a dartboard, is not feasible. A very tiny amount of these darts will hit an activated tile, even if they are correctly weighted by population density.
Instead we have to accept the game will need to make a compromise about this. The destination picking needs to be defined around two rules, which I call the “fair” rules to strike a balance between unbiased realism and having a playable game:
-
Rule 1: destination picking must be fair in relative terms between the possible destinations, not in absolute terms of what the entire world around a given station is. For example: one or more tiles have been activated near Barcelona and Lyon, so now you have 100 pax being spawned every hour who want to travel from Barcelona and Lyon (ignoring for now every other mechanic regulating spawn rate, like time of day). You now expand the network north, up to Paris, with every other variable being identical. The spawn rate for Barcelona -> Lyon must remain at 100 pax / hour, independent of any other destinations or expansions in your network.
-
Rule 2: the pax per unit of time rate who want to make given trip must be proportional to a combination of the destination population and distance from origin, never to network design. Situations like many pax going to some remote rural town because it is the only long distance destination from some corner of your network should not be reproduced after 1.12.
Efficient and unbiased destination picking for actual game usage
With these rules as the guide, it is now possible to design an efficient system to pick destinations from a given origin. For this purpose we will again use a CDF. Every activated tile will have a CDF, where each element represents every other activated tile in the map (yes, this is a quadratic cost). Why is this redundancy required? Because the probability of a certain tile being a possible destination is not just dependent on the population of the tile (which is independent of everything else), but it is also dependent on the distance from the origin tile (which is NOT independent). So for this reason this quadratic cost will be required to be assumed. It’s not too bad up to a few thousands of activated tiles, but at 10K+ activated tiles it starts going into 1GB of required RAM. I will benchmark and monitor the situation and see if there’s ways to improve on this, but for now this is the design.
A CDF weighted by population and distance is only half of the story. A final missing piece is required. Earlier in this post I mentioned that the pax spawn rate for a given tile will be proportional to its population (among other things). So absent of other factors, a given tile produces a certain number of pax per hour, and that’s it. If this system is implemented just like that, it will be have biased destinations. Why? Because the fixed pax spawn rate will just keep getting divided by the available destination pool. The pax flows to each destination will be correctly proportional to the population/distance ratio, but they will keep diminishing. Plus, before the network is developed, you will experience the stampede effect of many pax desperate to pick what few destinations are available.
The fix is to finally introduce in the game the concept of demand proportional to the available destinations. This new factor will modulate the base demand derived from the tile population, increasing it as more destinations become available. Or said another way, “waking it up” as more destinations appear, up to a certain level.
As an example, here’s a random tile in the center of Paris generating pax to other random tiles in some cities:
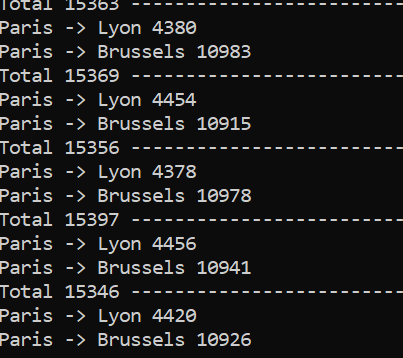
Each block of values is a given unit of time, with a total count of generated pax, and which destinations are picked. The numbers don’t mean anything! The distance weight formula is not tunned, I didn’t care to pick similarly populated tiles, etc. The point is to compare it to the next image:
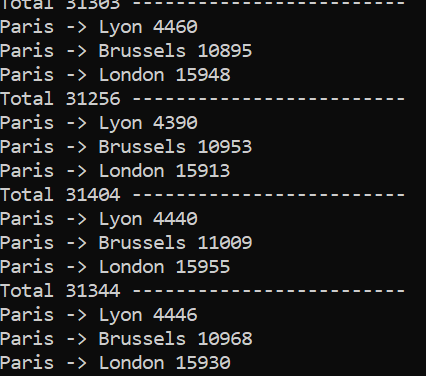
An additional possible destination has been introduced, yet the previously existing destinations are still being picked in the same numbers as before. This is accomplished by increasing the number of generated pax. Another few more destinations:
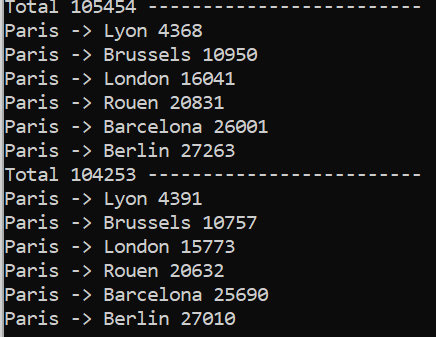
And the idea holds up. Finding the pax generation ceiling for the tiles will be interesting but it will ultimately be proportional to the ratio of the tile population and the total world population.
There’s still a huge amount of work left in 1.12, this is only the beginning. But this new system of pax generation and destination picking sets a new, very different foundation, which fixes long standing simulation limitations and opens the door to new features.