NIMBY Rails devblog 2022-07
Pax pathfinder dead ends
June ended with a working, but very slow pax timetable pathfinder. It was still a plain A* pathfinder, using dynamic edges derived from the arrival time at the node (station) based on the departures within the next 3h (the station waiting limit for pax, still the same in 1.5). Its heuristic was just as bad as ever, based on the geographical distance times the max possible train speed, but at least it was sound, and producing correct and optimal-looking paths.
I decided to try to implement one or two of the state of the art algorithms for timetabled pathfinding. I was probably going to fail but at least I would learn a lot in the process.
My first target was the next-to-best algorithm, called Timetable Labeling. Like all the algorithms in this space, it assumes there is some time available to pre-process timetables and the line network into a new data structure for very fast lookups later on. As such it is not very helpful when said timetables and network can change at any possible second. My idea was to make this preprocessing only an actual pause during game loading. Then once the game is loaded and running, new timetable builds would be done asynchronously, with the player having to accept that any edited lines or timetables would take some time to apply, and with visible UI feedback on the rebuild process. In the meantime the game would keep running using the old data.
The first part of TTL was something the authors called “temporal Dijkstra”, this is a modification of the classic Dijkstra algorithm for finding the shortest paths in a graph from a given starting node. Their modification is able to handle the fact that in a timetabled network there are connections which are only valid depending on the time of arrival to a node, including the fact the starting node will start its trip at a given time. I was able to implement this temporal Dijkstra algorithm, and it was much faster than I expected, but the next step of the full TTL implementation required to run this algorithm for every possible departure time in every station of the graph, and this of course was much slower. I was measuring multiple minutes on a map with 1600 stations and a total of ~1M departure events. This is fine when you have a server farm and do this once a day at 4AM, but it won’t fly for an interactive game. I then made a (crazy) optimization to this process by not clearing the Dijkstra hash table between runs (sorry Dr. Dijkstra). This is actually correct just in this instance, since the runs of temporal Dijkstra start at the latest possible departure in the week, then progress earlier and earlier. The data in the hash table is thus equal or worse than any newly produced path in the next run. If it’s worse, the algorithm just overwrites it and keeps expanding the path a usual. If it’s equal, the path is not expanded and a massive amount of work is potentially skipped in that run. I compared the results between my optimization and clearing the hash table (as you are supposed to do) and they were identical. This reduced the processing time from minutes down to the 50s range in my test map. Still slow but easier to handle.
I then started to implement the actual labeling part of the TTL algorithm. This part uses the set of the best paths found earlier and finds which ones are redundant (“dominated” in the paper). Dominated paths are paths which might be optimal for a given exact time of departure, but which end up being slower compared to if the pax just waited a little bit and took another, later departing path but with faster trains or connections down the line. The algorithm presents a way of systematically finding these situations and also to find out which intermediate stops function as a “pivot” stop, which allows to cut down paths into two sets of legs (called “labels” in the paper). Then it only stores the optimal labels for these pivots stops, sorted by the “importance” of the station (there is an entire chapter dedicated just to reason about how to rank stations by importance). After this is done, it is then possible to find the fastest path for a given start station at a certain time, by looking up which labels connect it to a pivot, and from the destination station, which labels arrive to it from a pivot, then walk down the pivot list until you find the fastest combination.
Implementing this was hard, and when I was halfway done with the label processing algorithm, I realized it was actually much slower than the temporal Dijkstra part. So the preprocessing time was back to minutes. I decided to stop work on TTL at this point, but I had learned a lot about the problem at hand.
A nice thing with papers is how they compare their results to other papers and the extensive citations they have, which allow you to explore a subject and find new ways to approach a problem if the paper at hand does not work out for your needs. I did just that. One of the algorithms they compare their work to is Connection Scan with Time Stream Representation. Like all work in this area, this algorithm preprocesses the timetable and network into another structure. This time it is just a flat, sorted (for their own specific definition of sorted) array of all the departure events in the network as taken while trying to arrive from a fixed origin to all destinations, within a time interval (so arrival time to origin plus an upper bound of travel time). If this is repeated for all departure times from all stations to all destinations, it is possible to build an index of all the possible best paths for the entire timetable. This was going to be faster than the TTL building process, but it still took minutes to run, mainly because the time range was in essence the entire week. I decided to discard this without fully exploring any more speedups, because it was still going to be too slow.
The vengeance of A*
At this point I realized the common theme of all of these algorithms is to produce massive maps of all possible best paths for all possible initial conditions, then process the results to compress/simplify/digest/etc into a different, faster to lookup and hopefully not to big structure (tho easy in the multi 100MB for TTL, for example). Then it dawned on me: isn’t the first part, all the best possible paths, looking like an A* heuristic? I don’t need the actual path for an A* heuristic, only the certainty that the best A->B path takes X seconds to travel, for the entire week (or some other period, read on). A* is very sensitive to the optimality of the heuristic, first to make the results correct and optimal (the heuristic must always be as fast, if not more, than the best real cost of the path), and for performance (so it does not take bad paths and expands useless nodes).
So I decided to use the time edge stream representation from the CSA paper just to find the cost of the best paths for the entire week, then use these costs as the heuristic in the A* pax timetable pathfinder. This resulted in a massive speedup for the A* pathfinder. It was now almost as fast as v1.4!
Of course the issue of the initial processing time remained. Too slow to make the user wait on game load, and too slow to run while playing after every line edit, even in the background. But it also had another problem: timetables will also bring real depot usage, so lines will have downtime. The heuristic will be too optimistic at certain times of the day, deviating from the real path cost, slowing down the pathfinder. These two issues were solved in a very straightforward way: run the time stream algorithm only for a 1h initial window, with a maximum of one day of travel. And then re-run it every 1h of simulation, or when a line edit is performed. With this much shorter initial window (keep in mind pax still can wait for 3h, it’s just 1h range for the initial possible station arrival) the preprocessing only took a few seconds, and on top of that it was calculating much more relevant path times for the given simulation time. v1.5 was saved (for now).
The revenge of the pax pathfind cache
Early on v1.5 development I removed the pax pathfind cache. It didn’t make sense anymore, since paths were only valid for a very specific set of conditions, including the current time of the week. The amount of stored paths was going to explode and the hit rate would be virtually zero, so it had to go.
But all the paper reading and experimenting gave me a new point of view when it comes to pax paths in timetables. The first realization was that time, despite being a value with a huge cardinality (24*3600*7 = 604800 for the game), was actually of second importance since it wasn’t the case a pax was capable of taking a train at every possible second of the week (it’s not a taxi simulator). The second realization is that pax only ever reason about the network while they are at a station, never in any other part of the trip (pax reevaluating the decision to remain in a train do so while said train is stopped in a station). And so I had an idea: what if it was possible to build a path cache which was only valid from the POV of a station?
So I tested just that. Finding a path from an origin station to destination station caches the path cost and the first step (line + stop to take from the first station) as data in the origin station. So a pax arriving at the station can quickly look up if its destination was already considered from there and just use the cached result. Extremely simple.
But as they say, there are only two hard problems in computer science: naming things and cache invalidation. And these cached pathfind results were going to be stale as soon as the day advances and a better path becomes available due to the time of the day. So the solution was extremely clear: the expiration time of an optimal pathfind is the departure time of its first step, always from the POV of the origin station. This is a perfect cache invalidation policy for this particular cache.
Now v1.5 stations keep a very small, private cache of all the recently looked up paths as themselves as the origin station. They only store them until the time of the departure of the first step of said path. This requires a tiny amount of memory and virtually no CPU to process. The overall speedup attained by this new cache is very large. v1.5 is now faster than v1.4, and it is more noticeable in larger maps with lots of pax.
With this new performance budget I tweaked some things. I increased station flow 3x, so 10K stations are going to be processed in around 1m or less, most of the time (always depending on the destination variance). I also finally made new pax be fully spawned pax with some special flag. They spawn with a valid pathfind already done, so they know they can start their trip within 3h and reach their destination. Since “new pax” don’t exist anymore as they did in v1.4, the “spawning slow down” which applied once the new pax pool of a station grew too much was not working, so demand was always at the max level for the time of day for every station. I decided not to fix this, since it’s more correct (the spawn slow down was here from v1.1 days, as help to try to make the game faster, when pax pathfind was easily 1000x slower than it is now). This increases the amount of spawned pax quite a bit, but despite handling ~30% more pax than v1.4 the test maps were still faster in v1.5.
The “station hall” idea presented in June won’t be necessary anymore thanks to this massive speedup. It does still have some interesting implications for gameplay rather than just performance, so it might be reconsidered in the future, but not for now.
Timetable UI
As I mentioned in June, v1.5 has three big tasks: pax timetable pathfind, timetable UI/logic, and train timetable AI. The pax pathfind part was now done and working much better than anticipated, so it was time to start with timetable UI and logic. I decided to delay the logic part a bit and just display the existing test data from 1.4 imports, which was enough to come up with some good interfaces. For now these interfaces are all read-only, until some (significant) obstacles with timetable logic are solved.
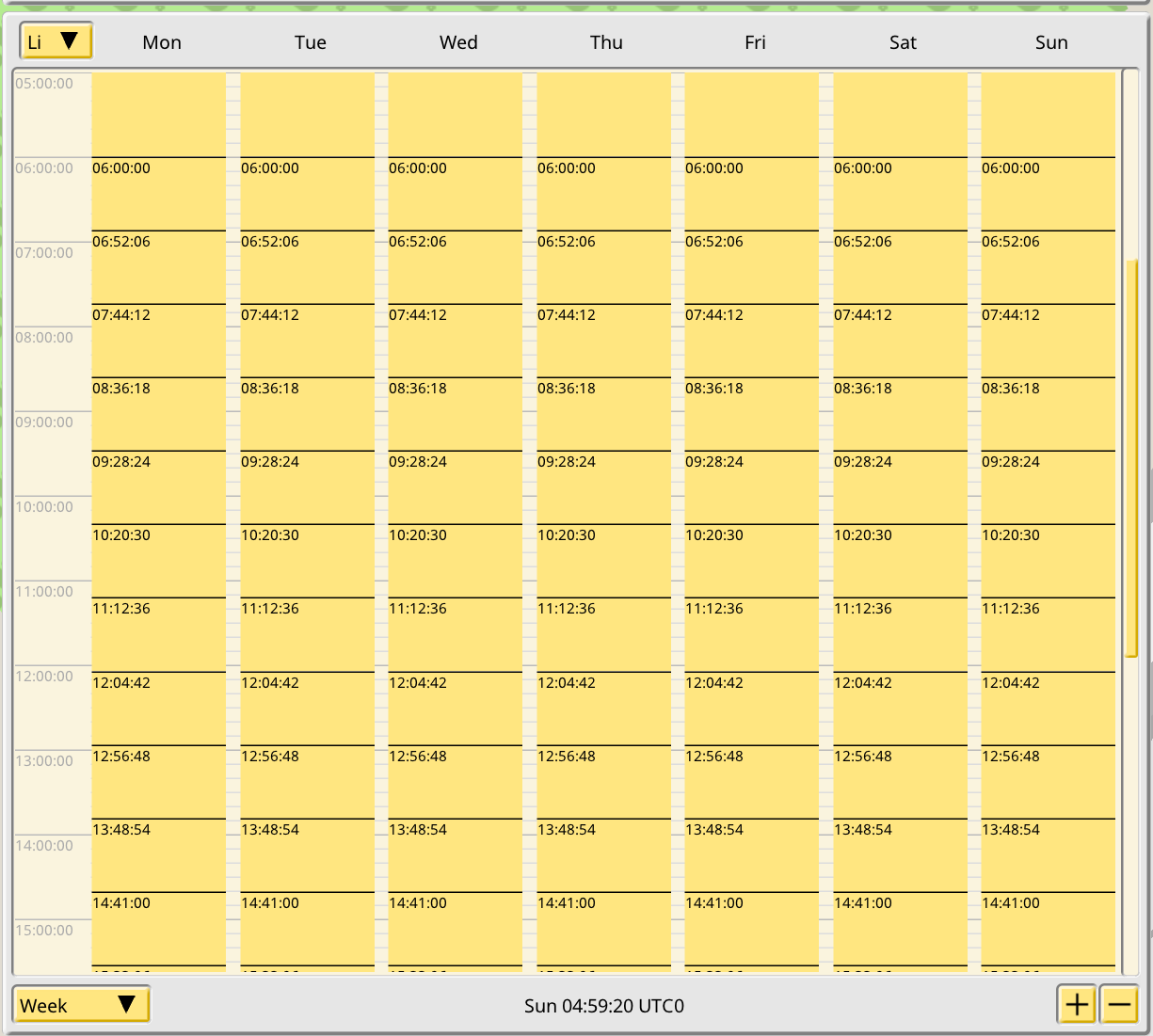
The screenshot shows the timetable from the POV of a train. Trains store a set of “runs”, with a run being a full run of their assigned line (the old train scheduler is gone; trains only have one line). Runs must cover the entire week for the train. Runs have a starting time, so using this starting time plus the line timing it is possible to calculate all arrival and departure events for all stations and all trains.
As for the UI, the basic widget is an table displaying boxes over some time axis. There are controls to pick a time zone (only for display; all times are always stored in UTC0, and line editing will allow to set a preferred input timezone, but only as an UI detail for the player, not for the data), to change the amount of days displayed and to zoom in/out. This widget needs to be very fast since short lines will have thousands of these boxes, which from the POV of a train are runs, and even more from the POV of stations, which are displayed per-stop:
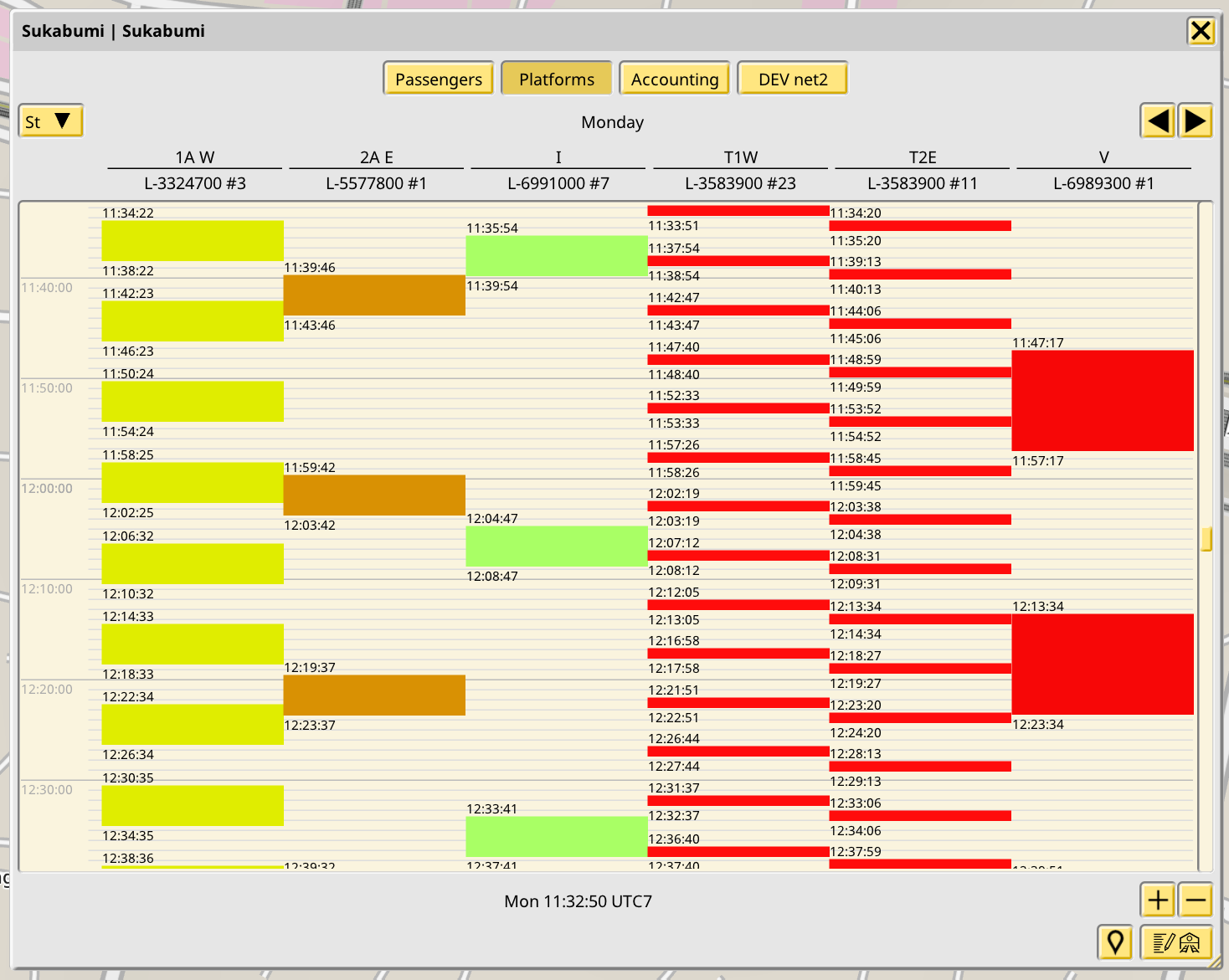
Here the boxes represent a stay of a train in a given station platform for a given line+stop combo. This is displayed fixed in single day mode, and for big stations with lots of stops it might become a bit messy, so this table is part of the station info window and it scales horizontally with it. It might still not be enough so I will see about horizontal scrolling later on.
Lines timetables display all the train runs belonging to the line for a given day:
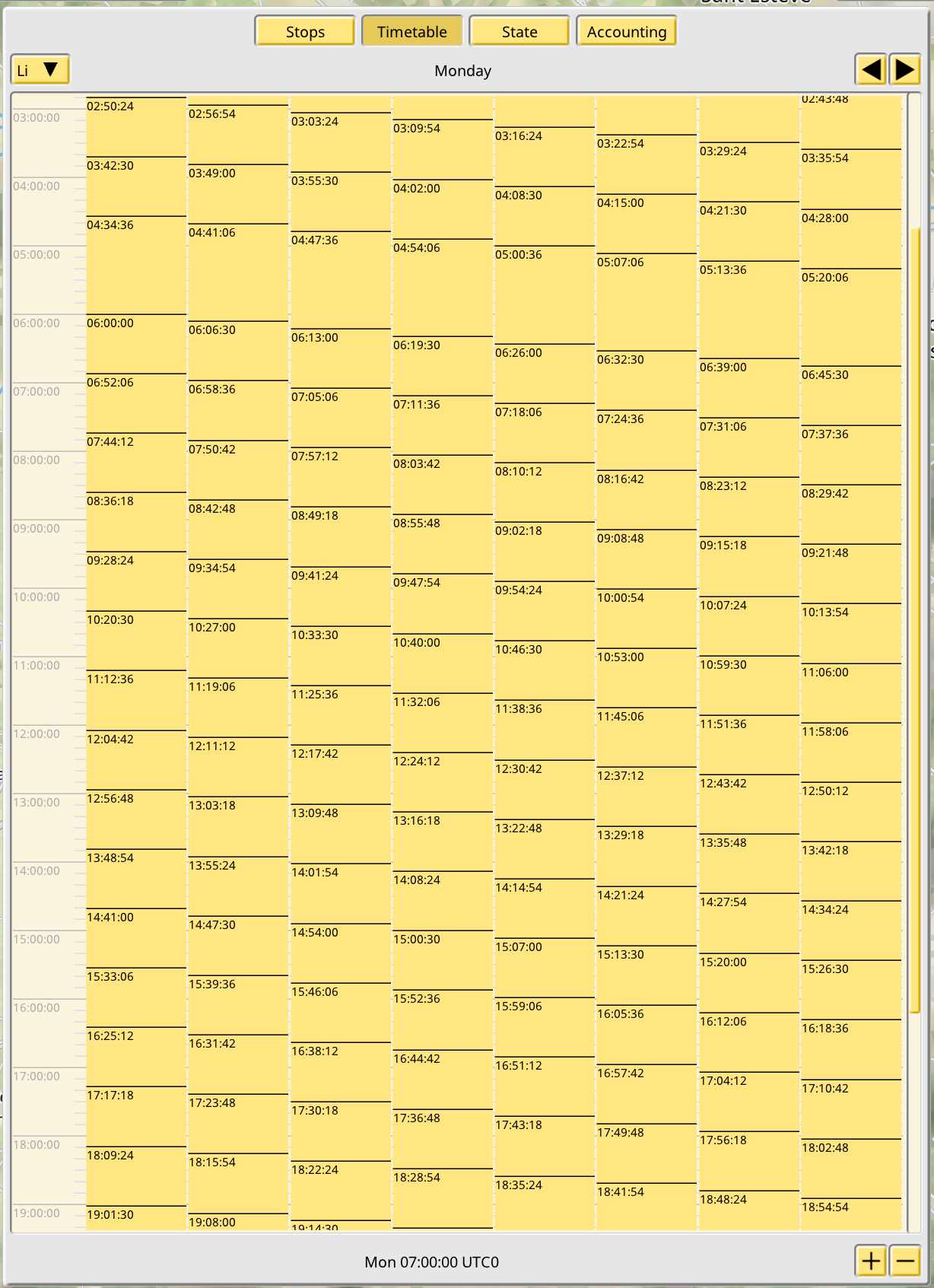
Here you can see how the 1.4 data is imported. A fixed timetable is generated using an arbitrary launch time for the first train of the line, and then an interval is added to launch every other train in the line. It is also possible to select a run and see the specific times for every stop:
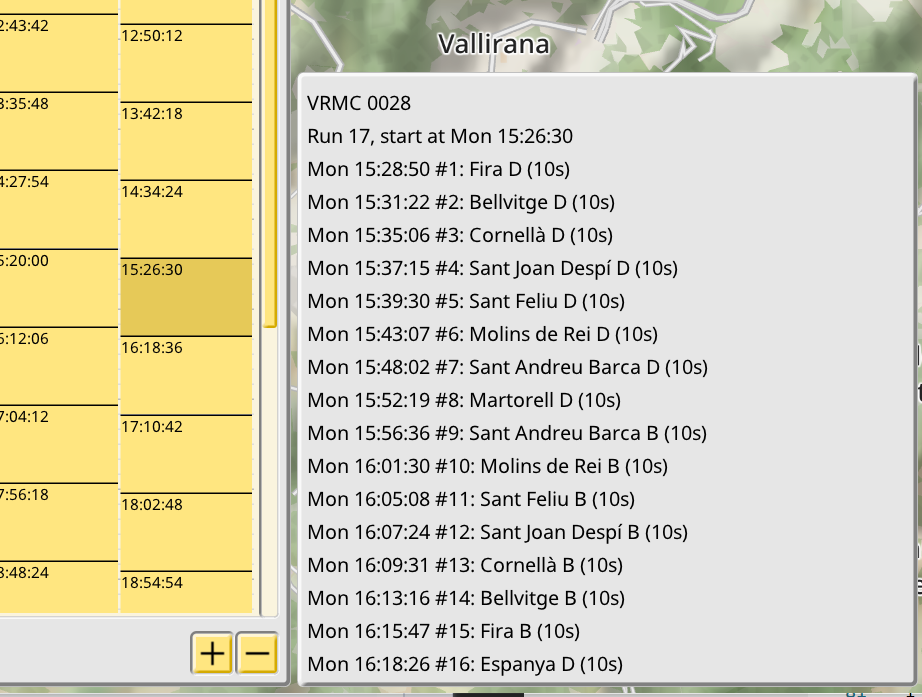
This interface is very rough at the moment, since it will depend on decisions taken on the logic of timetables, which are an open and ongoing problem.
Timetables current status and problems
With pax pathfind solved and the (read only part) of the UI at 75%, it was time to finally decide on a set of logic rules for how timetables work and are edited by players.
I decided to keep the train run system introduced in June. Lines are not going away and trains just run lines, so it is natural to use such a system. It is also a nice middle ground between fully abstracted timetables and a train event system, where every train stop is a full isolated object from everything else. And it does not preclude per-stop timing if desired: a run only has one fixed time, its start time, but nothing prevents adding extra data to the run to do things like making one or more stops wait for longer to properly “bump” times around until a desired time is achieved.
But thinking about the interfaces and procedures to implement such a feature and making it accessible makes it clear it is complex. The mere act of moving some run 30s down the line so some stop lines better with some other line stop, means a lot of things. It means every subsequent run for that train needs to be bumped 30s too. It also means every run for every other train in the same line probably needs to be moved down. And lines virtually will never neatly line up with 24h divisors (or weekly ones), so the concept of some runs lasting longer than others needs to be introduced in order to handle longer “end of day” runs. This in turn means extra run duration time which must be spent somewhere, probably waiting in (one? a set? which ones? and the other trains which also want to stop?) stop of the line. And all of this is not even considering depots, which are likely to be delayed to some >1.5.1 version.
There are a lot of decisions and compromises to make, and a quite a lot of automation to build to support it all. For now this is the extent of line timetable editing in the game:
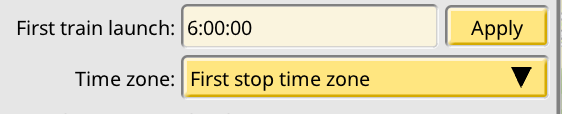
This basically re-runs the 1.4 import code and synthesizes a valid, if dull, timetable. The ideas about editing single run start times, bumping runs around to accommodate these edits, consuming extra duration times on stops, etc., are not implemented yet, only sketched as ideas. I’m not even sure if this is the right design at this moment. So I’ve decided to pause the UI/logic part of timetables, and jump to train AI. I hope this will give me the insights I need to make a decision on timetable logic, plus after nearly two months of development I really want to see trains actually following timetables.
Track bulk editor
I snuck some unrelated, smaller features from time to time to get my head away from the hard bigger tasks. In July I implemented an often requested feature, although it’s not always being suggested in this format:
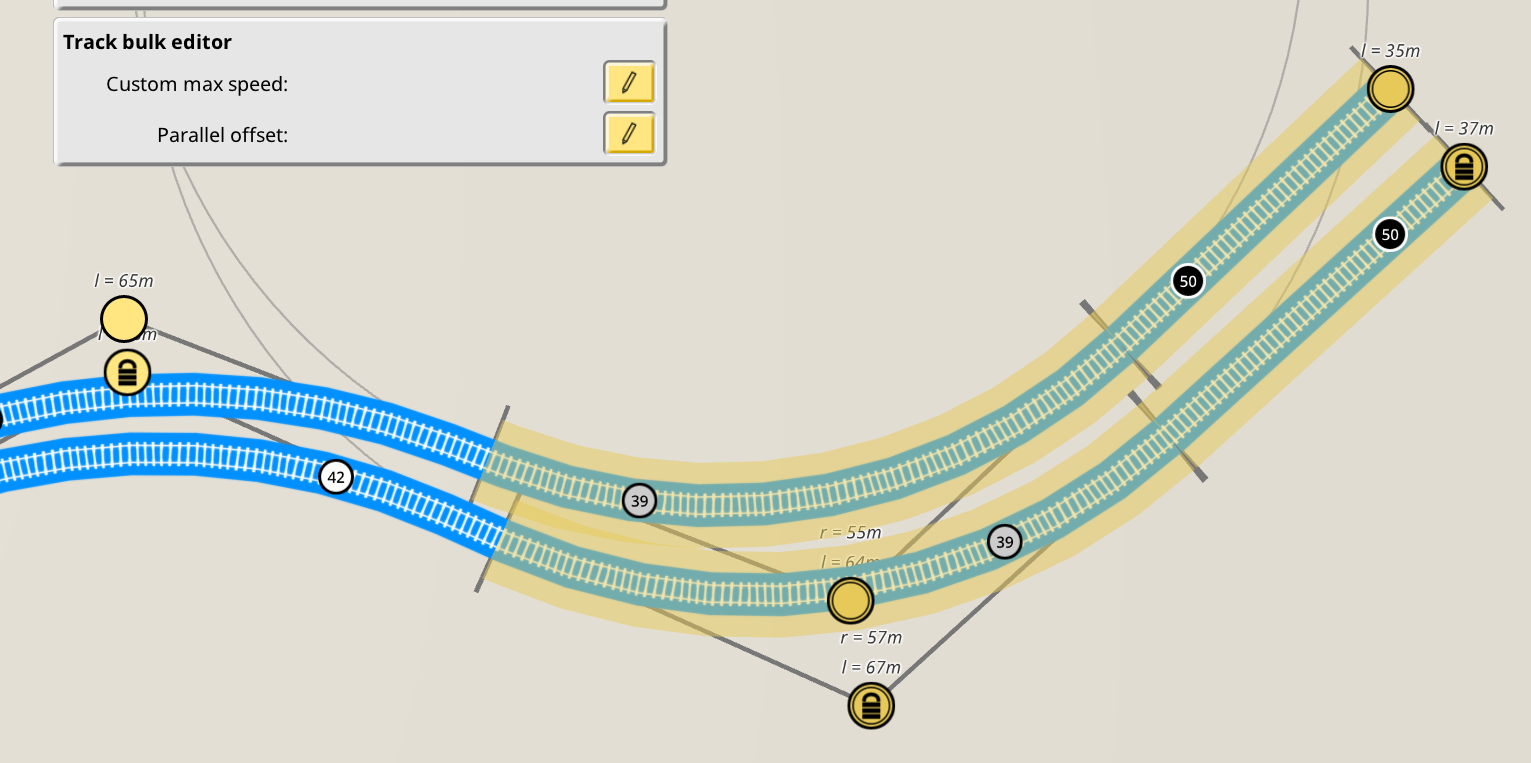
This new track editor panel will be displayed when a set of tracks is selected, and it will allow to set some track properties in bulk, for the entire selection set. Some settings will silently fail where they make sense to (not all properties can be set on built tracks, for example). For now there’s just these two properties as seen in the screenshot, and I’m sure some others will be added in the future, but I suspect just these two are going to be quite popular :)