NIMBY Rails devblog 2020-03
Internal development notes, very slightly cleaned up and commented a month later.
TL;DR: async search engine, saner UI API, new forward compatible save format, short codes, station sanity, better track fusion
Async search engine
- async search engine queries
to not block ui
map API returns result or a busy flag
internally it keeps the result of the last query, and the query parameters
if requested search matches last query, returns it
if not
if one connection is searching something already
do nothing! since UI is immediate mode, it will ask again on next frame
if no search is active, fire up a search for the request. keep query params for the cache
show loading... in ui while busy
use async and futures at gis::Map level, gis::DB is already built with auto queuing for connections
check if local gets stuck or is normal behavior due to slowness in debug mode
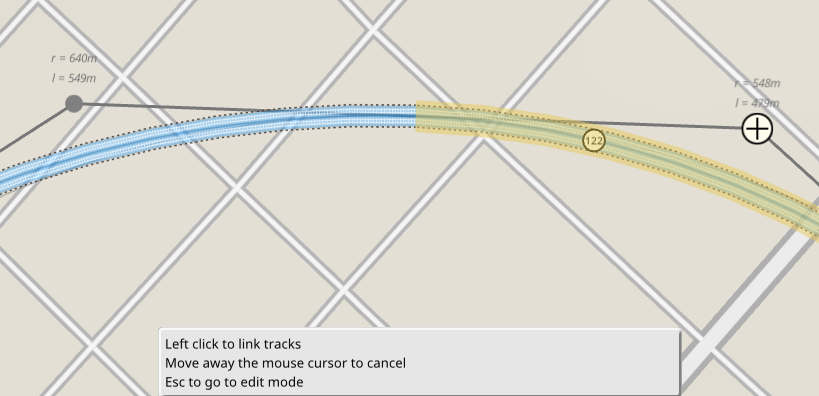
Given the hundreds of thousands of region, city, town and area names available in the game database a search engine is vital when exploring the map. The game features a search engine, but even with a fully indexed database and optimized queries it’s still possible for some searches to take seconds, especially in development builds.
Now search queries are performed asynchronously from the UI. A search task is launched in a dedicated thread with a dedicated private SQLite connection just to perform the search, keeping the UI at 60FPS even when the search itself is pegging a core at 100%.
Saner UI API
- move shell::ui_/UI stuff to proper shell::ui namespace
- kill UI css-like selector+style system, replace with explicit ui::style variables
user code copy() from other values in ui level variables, or shell level, or local the func/scope
ui(x, ...) takes ui::Style now
capability to take local scope UIStyle solves massive PITA about styles being far away from the widget code
and favors local usage which was the pain point in prev system
test local style values in main menu
implement child styles and tag styles with a simple matcher
for compat to not redo the entire ui...
use neater child()/clone() API which returns emplaced and by-value copy
fix child matching by parent rules to be non-overriding
accumulate all matching parent modifications into an empty style with overriding, in order, then apply result to child, non-overriding
fix child matching to consider number parent tags, not child tags
- fix new style system breakage
wrong w for trash button
slim form labels are wrong in line editor
- move style values and constants into ui::style namespace
- cleanup (some) panel creation
add panel helper to create the various modal panels
also creates the initial seq to save a nesting
The UI system in NIMBY Rails uses a layered approach to its API. At the lower level there is a forked version of nuklear. Then on top of it the UI system does its own layout based on randrew/layout. And at the very top a custom, immediate mode -like API wraps and hides both libraries. I really like the immediate model, but style and layout wise, I found the existing solutions lacking. The layout part I was able to solve with the awesome randrew/layout (although it involves a very strange 2-pass solution since the UI code is written in immediate mode style). But for the styling I rolled my own system. An earlier iteration (missguidely in hindsight) tried to copy some concepts of CSS. The system is now based on “style values”, where simple copying and composition, as native to C++, is used instead, for much cleaner semantics.
Forward compatible saves and flexible serialization
- serde v2: forward compatible, versioned visitor for model, without using libnop
like https://yave.handmade.network/blogs/p/2723-how_media_molecule_does_serialization
base types and lib collections are not versioned
base model objects like RectI aren't either
other model is
- while doing saves v2, temporary support of both v1/v2 saves in both save code and UI to convert the trailer saves
- saves v2: based on new serde.h, new save data wrapper, move code to sync from mainmenu
header: NOT versioned, fixed as file save id, flags, version, hash of preview data, hash of game data
preview: data for preview display in save picker
game: a game serialization
move save/load code to sync
move state setup to shell/state.cpp
cleanup main menu logic on overwritting saves
keep v1 compat to migrate trailer saves
- io coder for serde
std::iostream based
use varint.h based on the protozero stuff
- hook up new load/save code in sync/saves.cpp
- convert trailer saves to v2 format and delete old saves
- remove v1 saves load code
- keep old saves with old build in incoming
- transition sync to new serde
sync will be redone in the future, do minimal effort for compilation of libnop removal
- remove libnop from VS proj
not from repo, req by wrangler
check paths in proj files too
- divide serde into ser and de, preserving constness for ser
cannot be fully done in a template way, needs preprocessor kludges for model objects
- serde: handle any sized enum with internal int64_t casting
remains bin compatible since it was fixed at 4 bytes before, which encodes into varint
The original save system was based on libnop, a very easy to use C++ serialization library. This simplicity allowed me to bring up save support fast, but it was time to look into a more serious effort for saved games. The key is to support versioning, so a save game can advertise its game version and the loader code and make decisions on how to interpret the data in the context of a newer one. Ideally this process should be as easy and as automated as possible. I decided to go with the approach detailed here, with my own interpetation of the API using some light C++ template features (I save the heavy C++ template features for a later blog post :).
// ...
inline void visit(int32_t const* obj, Serializer* io) { io->num_integer(obj, 4, false); }
// ...
void visit(gis::Coordinates* obj, IO* io) {
visit(&obj->x, io);
visit(&obj->y, io);
}
In the new system there is a visit() function for every type in the game data model, from the humble int to the structs that hold all the game data. Only the most primitve data types declare any IO to perform, and it is the responsibility of the IO object (itself an specialization of an abstract IO interface) to decide what to do with the memory address, to read or write to it. Simple structs can directly call visit() on its members.
#define _serde_vector_like_serialize \
size_t s = obj->size();\
visit(&s, io);\
for (auto const& elem : *obj) {\
visit(&elem, io);\
}
#define _serde_vector_like_deserialize \
size_t s = obj->size();\
visit(&s, io);\
if (obj->size() != s) {\
obj->resize(s);\
}\
for (auto& elem : *obj) {\
visit(&elem, io);\
}
template <typename T> inline void visit(std::vector<T> const* obj, Serializer* io) { _serde_vector_like_serialize }
template <typename T> inline void visit(eastl::vector<T> const* obj, Serializer* io) { _serde_vector_like_serialize }
inline void visit(std::string const* obj, Serializer* io) { _serde_vector_like_serialize }
inline void visit(eastl::string const* obj, Serializer* io) { _serde_vector_like_serialize }
With some care even standard C++ containers can easily be handled, sometimes using local variables in the visitor function to encode the length. And thanks to templating it’s easy to support containers with any contained type, with full serialization available for their contents. Note that this example is the only one showing the real style of the code, using const to distinguish between serialization and deserialization. The other examples are simplified, and the hack to not repeat code in those structs that do not require it is not shown.
// ...
template <int32_t added, typename T>
inline void live(T obj, IO* io) {
if (io->version >= added) {
visit(obj, io);
}
}
template <int32_t added, int32_t removed, typename T>
inline T dead(IO* io) {
T value;
if (io->version >= added && io->version < removed) {
visit(&value, io);
}
return value;
}
// ...
void visit(model::Track* obj, IO* io) {
live<v_genesis>(&obj->id, io);
live<v_genesis>(&obj->serial, io);
live<v_genesis>(&obj->build_status, io);
live<v_genesis>(&obj->kind, io);
live<v_genesis>(&obj->prev_id, io);
live<v_genesis>(&obj->next_id, io);
live<v_genesis>(&obj->point, io);
dead<v_genesis, v_cleanuptrack, double>(io); // radius, not deleted, just undesired in saves
dead<v_genesis, v_cleanuptrack, bool>(io); // station_plaftorm, made redundant by station_group_id
dead<v_genesis, v_cleanuptrack, double>(io); // station_platform_footprint_margin_start_t as data
dead<v_genesis, v_cleanuptrack, double>(io); // station_platform_footprint_margin_end_t as data
dead<v_genesis, v_cleanuptrack, double>(io); // station_platform_footprint_margin_half_thick_meters, lookup in kind
live<v_genesis>(&obj->station_group_id, io);
live<v_genesis>(&obj->attached_to_id, io);
live<v_genesis>(&obj->attached_to_t, io);
live<v_genesis>(&obj->attached_linkable, io);
live<v_genesis>(&obj->attached_by, io);
}
The previous snippet is the (de)serialization method for the track data in the game, as it is right now. The visit/dead calls themselves are actually wrapping a call to the (very) overloaded visit() function, which perform the version checks as described in the linked article, reading and then skipping data. It is also possible to use the dead data to improve the loading of old saves.
Short codes for trains and lines
- introduce short codes
for trains and lines
model/saves/editor
add a little bit of string gen for short codes
- vis short codes
inside train icon, both train and line code
- optionally allow train decals to inherit line color
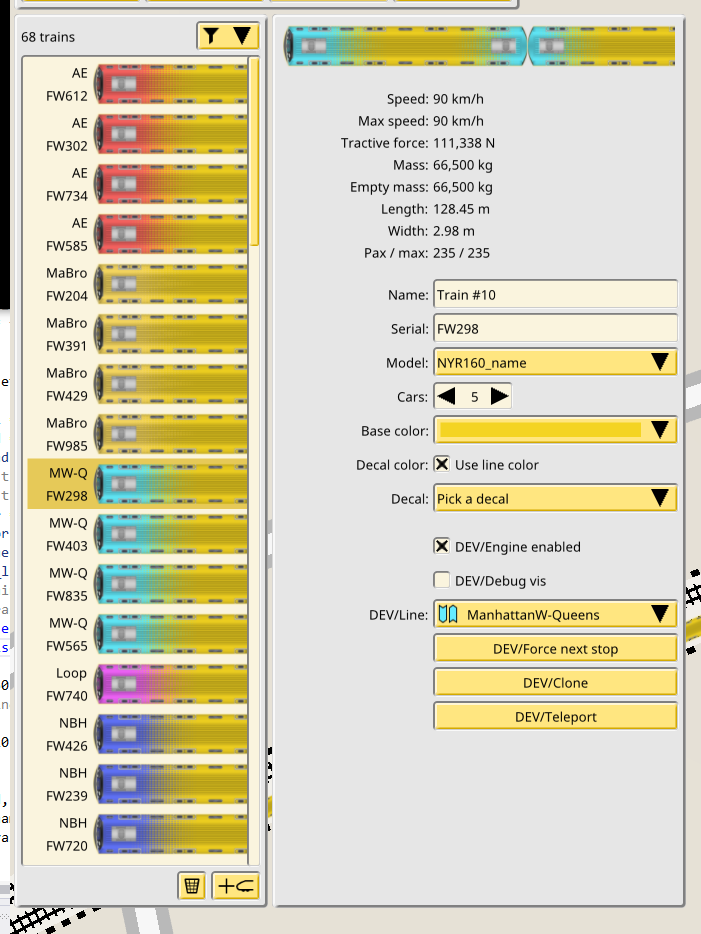
Trains and lines alread had names, but those fields are meant to be as long and descriptive as the user wants. There is now an extra field to name trains and lines, intended to be very short and displayed in more places in the UI:
These new short codes also helped provide a better listing in the train editor, with more empty background space allowing for a better visibility of the selected train. A small but very sensible feature was also added to this editor and to the train data model, to automatically use the line color as the decal color.
Rewrite automatic station fusion code
- stations sanity fix: keep the current maximalist flexible idea, but only process on update()
so no processing just after modification
introduce queued pending stations
station groups are only optimistically updated to not contain invalid ids
any edited station tracks dirties its station group, to be processed
update alogrithm collects all dirties, and all tracks thant belong to them even if not diry
and also all stations that overlap the tracks even if not diry themselves, and all their tracks too
then finds overlapping clusters of tracks with an exhaustive search
since this considers even non-dirty tracks, and always considers all tracks of all stations, the clusters become the truth
each cluster is then assigned to an existing station, replacing its tracks, or a fresh one is introduced, if an existing station was already fixed
- test modifcation by deletion with new station code
- fix: erase empty stations after fusion
- fix: restore priority when deciding which station to keep and which one to create
sort the clusters and keep using the naive iteration
then select the relevant station id for each cluster, not just *begin()
station_group_importance is still there, use it
- fix: restore platform numbering after new station code broke it
old station updater code, out of tree now, has it
When designing the station system in the game I went for the most flexible idea, while also being the easiest possible idea. Any combination of track platforms can form a station as long as they respect the overlapping rules (so no two unbranched ground tracks can overlap, but any amount of metro tracks can overlap them, for example). Grouping platforms into a single station is as simple as making sure their perimeters touch at some point. De-grouping them is as easy as moving one away from the other, splitting them automatically without explicit user action to do so. This has to support any ideas the user may come up with, including setting up platforms in a ring, or in a “U” shape, and any possible addition and removal to those.
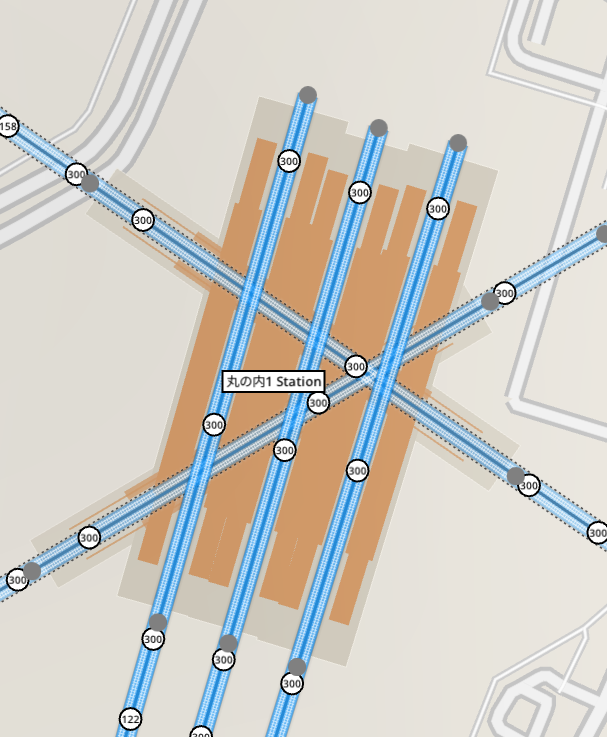
The original code to allow all of this was a mess and operated in a eager way the moment a platform was edited in some way. This was very brittle and was not going to survive the future cleanups and refactors required for robust multiplayer or editor undo (yep, those are coming, and in fact already present in prototype form). The new code instead uses the same pattern the non-station track system uses, by having a separate “update” logic pass after the user is done editing for a frame.
Do not introduce extra track segments when linking tracks
- remove the need to create 2 tracks when linking tracks in the editor
the original codes was deleting the stub tracks from stations, triggering station deletion
so the intermediate extra track was added to "receive" the deletion
but this is not needed anymore since track addition mode always creates a track when clicking the + control on a track end
so there's always a temp track to delete, never deleting the sibling or the hit
deletion is only ever made on the original creating_track_id
sibling and hit tracks only get linked or unlinked, never deleted
Another early artifact from stations was having the station “track tip” be part of the platform itself. While this is correct in principle, it lead to problems related to the logic the game uses to keep the track segments consistent on the face of deletions. Eventually this was improved by adding a non-removable short track segment in front of that tip, and having this segment be the only linkable part of a platform.
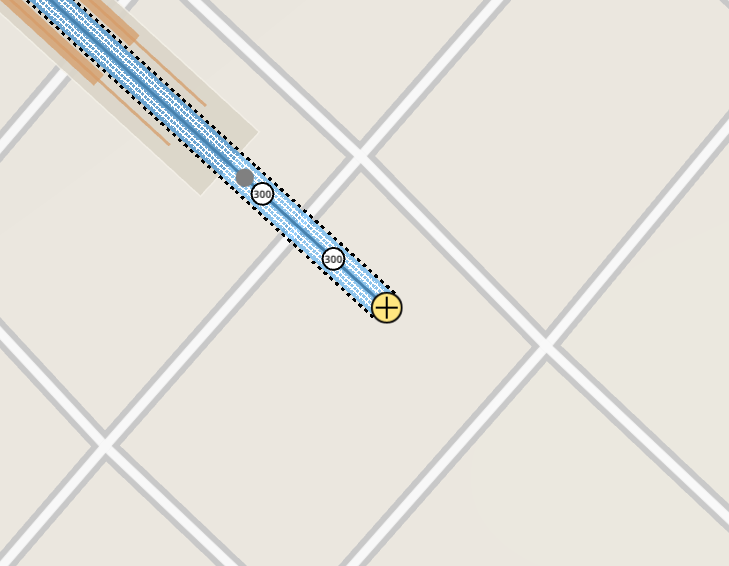
The relevance of this change was to enable general track linking to be exactly that, just linking two track segments into a single one. Since the in-progress track blueprint of a track being linked is temporally deleted, such a deletion could cause a cascaded deletion of the station. To fix this track linking always inserted an extra track link. But with the new platform tips it was now possible to restore the former, correct track linking behavior: