NIMBY Rails devblog 2025-05
WARNING! This post is very technical, much more than usual. It is of little interest for virtually all players. NimbyScript, once it is introduced in the game, will receive a proper guide and examples. This post is NOT the NimbyScript guide and examples.
Faster game DB with better memory usage
The past couple months have been focused on NimbyScript, but some other developments, related to it, have also been implemented. One of them is another redesign of the game database, which stores every object in the game. This database, now at version 3, is now based on generational IDs mapped over a compact storage pool of blocks of memory. The ID scheme is similar to those used in ECS systems, like in flecs. Although NIMBY Rails is not based on the ECS architecture, it takes some elements from it. For example starting in 1.16 the train simulation state is based on components, and now in 1.17 most object IDs will be generational IDs. Using these IDs is almost as performant as using direct pointers, but with the safety feature of being able to know if the ID points to a valid, expected piece of memory or not. They also help with keeping memory allocations compact, since part of the ID is a linear index into memory which is kept as low as possible, automatically reusing memory.
This new database gives a noticeable but minor speedup, and an improvement in memory usage. It also setups the code for a possible future evolution of the data model, to partition some “mega objects” like Schedule, which basically contain everything into a singular object that can be megabytes in memory. This is undesirable but it was done in the past because the old database system was so bad at fragmenting memory, and also because it improved multiplayer synchronization in the old, changeset based system. But both of these concerns have now been removed so the way is clear to attempt this further evolution of the data model, but implementing the importer for existing saves might be too complex to be worth the effort.
Bounded track pathfinding
A “bug” that surfaces from time to time is players setting up lines or orders which require an impossible track path, causing the game performance to dive into low FPS numbers and less than 10x sim speed, on saves which are otherwise running fine. The reason this happens is that, in a very well connected and very large track network, the track path finder ends up visiting every possible track segment while trying to find a path between two impossible to connect points in the network.
A possible way to solve this in the game code is by introducing extra information in the network. For example connectivity information, which divides the network into connected clusters and automatically discards paths when the origin and destination are in different clusters (this is done in the pax pathfinder). Unfortunately the size and shape of the track network, and the capabilities of the track editor to make any edit of any size at any time, including with the simulation running, make this very hard. It would also introduce a fixed, large, extra performance cost on every track editing operation.
A possible alternative, which I am going to trial in 1.17, is introducing a track path find bound. This means that the track pathfinder will ignore paths which reach certain threshold, bounding the maximum time it will spend trying to find a path. This bound can take many shapes, but for now it is formulated like this: the track pathfinder won’t consider paths which are over 100km long or over 10 times longer than the geodesic distance of the origin and destination points, whichever is longer. In other words, only paths which are at most 10 times as long as the straight line between points, with a large lower bound for the usual technical maneuvers that can easily be more than 10x.
But what if you really have a line leg which needs to be 10x as long as the straight distance, and it’s longer than 100km, like some very remote mountain climber? You can still use waypoints! If these kinds of legs really go over 10x, you can still insert one or more waypoints halfway. All the saves I tested report 0 errors with this new limit so far, but beta testing will be required to adjust it up if needed.
NimbyScript dead ends
NimbyScript has been my partial focus since early this year, and nearly my sole focus since 1.16 was mostly done. I will explain what is exactly NimbyScript and what it is for, and its current state, but before I get to that point, I want to explain and show some intermediate steps I had to make to reach the current state of development. Mostly dead ends, but they were very helpful in figuring things out.
Node graph programming
At a couple times in the past two months I was very close to give up and cancel the idea, and replace it with something simpler and dumber, like some sort of super configurable signal plus even more order configuration options. An offshoot of this idea, blending the concepts of “too complex UI” and “too dumb programming language”, is node graph programming. Basically, instead of plain text which follows a syntax and grammar, node graph programming is about a graphical canvas where you drop and drag boxes representing some kind of object and/or action, and linking them together to represent the flow of information and the sequence of actions.
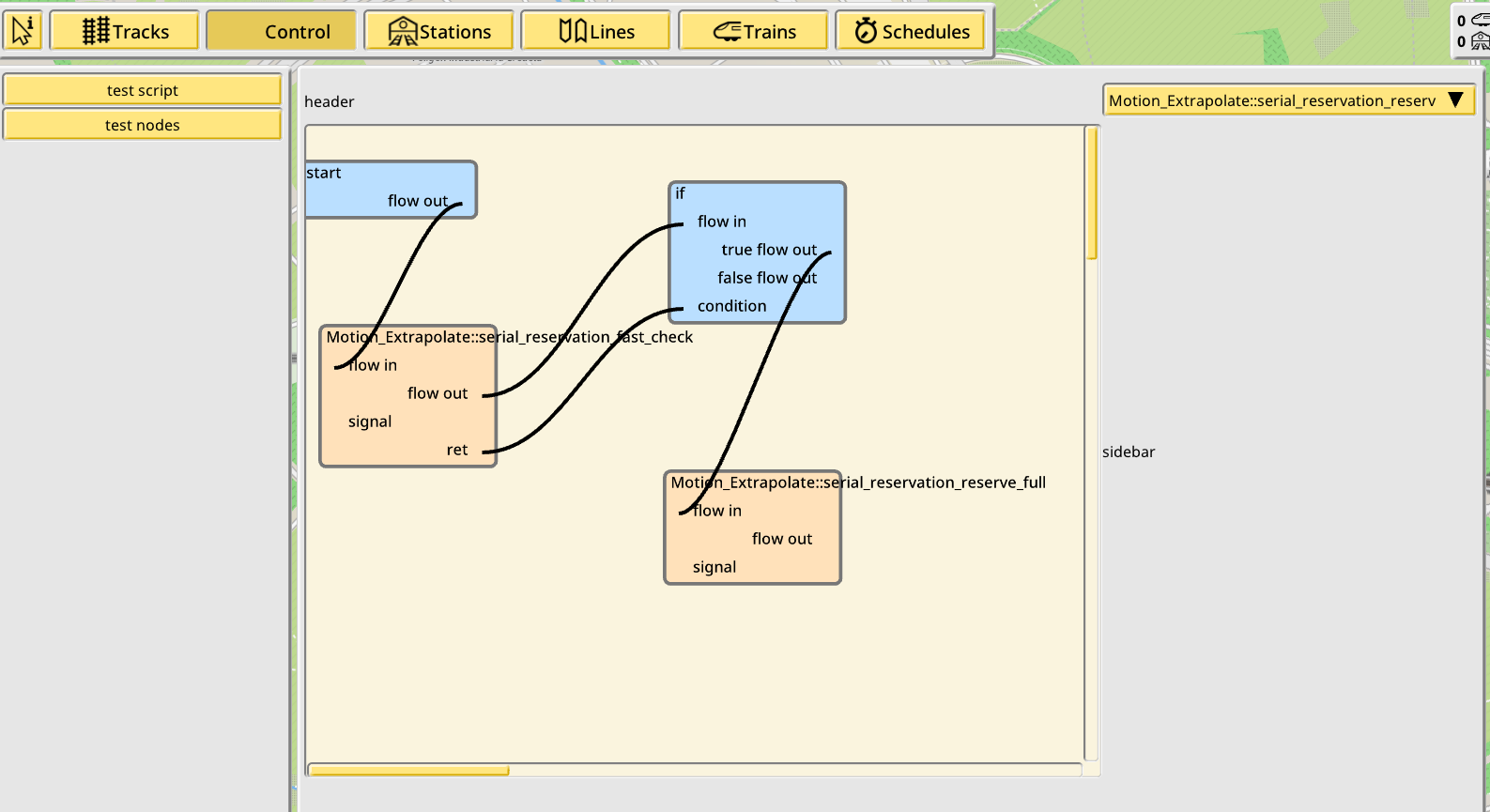
I was inspired by Unreal Blueprints, which also introduce functional and reactive concepts to the programming model, making the whole idea a lot better than just a graphical representation of textual programming. Unfortunately it is also a lot harder to implement, and a dumber programming model is not really worth the effort. Nonetheless I still made sure to at least finish up a bit the graphical frontend part because such a graphical canvas could have other uses.
Plain C for user level code, JIT compiled
For the reasons I will explain later on, using TinyCC as a backend for a custom language was already in my plans, and I already posted about it in the last couple devblogs. But I also wanted to at least try how it would look and feel to offer C as the scripting language. It was clear to me from the start this is just not possible for the reasons I will explain later on, but the effort is not for nothing, since if I went with a custom language it will anyway compile down to C and even if that generated C code looks nothing like proper hand written C code, it still needs to call the same APIs.
To make this basic test I isolated some of the C++ code related to signal processing in a few functions, so that most of the processing of a path signal could be done with a few calls and a couple conditionals, at a high level. This is more or less the desired level of abstraction for scripts. The following C code is not representative of the real C++ code of the game. I’m not going to explain these APIs, the names are suggestive enough and this is only for illustrative purposes, and to compare it with a snippet of NimbyScript later in the post.
// remember: this is not NimbyScript, it is plain C
#define r_stop_changed 0
#define r_stop_kept 1
#define r_cont_changed 2
#define r_cont_kept 3
int64_t signal_stopped_serial_apply(void* ctx, void* self, Motion* motion, Signal* s) {
bool changed_destination = Motion_Extrapolate_signals_try_change_destination(ctx, s, false);
if (!Motion_Extrapolate_serial_reservation_fast_check(ctx, Signal_id(s))) {
return changed_destination ? r_stop_changed : r_stop_kept;
}
Motion_Extrapolate_serial_reservation_reserve_full(ctx, Signal_id(s));
OptionalMotionDrive* opt_drive = &Motion_drive(motion);
MotionDrive* drive = test_deref_optional_Drive(opt_drive);
if (drive) {
MotionDrive_waiting_signal_id(drive) = 0;
MotionDrive_waiting_signal_last_check(drive) = 0;
}
return changed_destination ? r_cont_changed : r_cont_kept;
}
int64_t signal_moving_full_apply(void* ctx, void* self, Motion* motion, Signal* s) {
bool changed_destination = Motion_Extrapolate_signals_try_change_destination(ctx, s, false);
if (!Motion_Extrapolate_serial_reservation_fast_check(ctx, Signal_id(s))) {
OptionalMotionDrive* opt_drive = &Motion_drive(motion);
MotionDrive* drive = test_deref_optional_Drive(opt_drive);
if (drive) {
MotionDrive_waiting_signal_id(drive) = Signal_id(s);
MotionDrive_waiting_signal_last_check(drive) = 0;
}
return changed_destination ? r_stop_changed : r_stop_kept;
}
Motion_Extrapolate_serial_reservation_reserve_full(ctx, Signal_id(s));
OptionalMotionDrive* opt_drive = &Motion_drive(motion);
MotionDrive* drive = test_deref_optional_Drive(opt_drive);
if (drive) {
MotionDrive_waiting_signal_id(drive) = 0;
MotionDrive_waiting_signal_last_check(drive) = 0;
}
return changed_destination ? r_cont_changed : r_cont_kept;
}
The test worked fine! The previous piece of code is included in the game as a plain text string, compiled on the fly, and then every signal calls upon those two functions as part of the normal simulation processing. There is no performance hit and no bugs or issues.
Although this was not NimbyScript, it validated the low level parts of the idea, and it showed it was possible to integrate it with the rest of the game. Indeed to reach this point I also had to introduce all the “glue” concepts like exposing C++ APIs into C, C++ types into C (these function-like calls Signal_id(s) are actually C macros for C++ struct access auto generated from C++ metadata; and “OptionalMotionDrive” is wrapping a C++ std::optional<Drive> for example), a type safe abstraction for callable script functions from the C++ side, etc. These systems together with the TinyCC compiler are the “backend” of NimbyScript.
Seeing this example working encouraged me to not give up on the “frontend” part of NimbyScript, the actual language players are expected to learn and write. But I had imposed some very hard goals to myself, and it took me six weeks after this successful test of the backend part to achieve a breakthrough in the frontend part that made that convinced me that yes, what I wanted was possible and doable.
Six weeks of agony
Let’s list what I wanted from NimbyScript. These goals first guided my search of a suitable language, and when it was clear such a language did not exists, my own designs for NimbyScript.
- Must perform like C/C++. The pure computation parts of the language (not the “call in/out” parts interacting with APIs) must perform at a level similar to compiled plain C.
- Zero call overhead compared to C/C++ code calling to/from C/C++ code. Some languages have a good performance in their pure computation parts, but it all collapses once they need to make any calls which cross the language boundaries.
- Zero data marshalling cost. Related to the previous item, the in-memory representation of data should never require any conversion step between C/C++ and the language, for zero performance hit.
- No garbage collection. Nimby Rails does not use a garbage collector, and I am not going to introduce a GC in the game just for the sake of scripting.
- Memory safe. There’s a variety of meanings to this, and I am open minded to accept many of of them, but some won’t do it. If “memory safe” means things like “every possible non-word data sized object has a reference count, but it’s still possible to crash by doing some extremely common things the compiler won’t stop you from doing” sorry but I will keep looking.
- Source code must be runtime loadable and executable. It is not acceptable if the language execution must undergo some intermediate on-disk state like DLLs or bytecode files. This is because I want the game itself to be the only thing you need to develop scripts, ideally at the level of providing in-game editing of script. If it’s mandatory to run some external tool as a previous step I consider I’ve failed this goal.
- It should not require some enormous dependency like the LLVM or the CLR, that is multiple times bigger than the game itself.
I was chasing an unicorn. To move it out of the way ASAP: yes, it was Rust, that’s what was in my mind all the time. But as per the last point I wasn’t going to bring the LLVM into the game, plus Rust is not designed as a script/extension language. It allows you to do too much stuff.
In fact as I considered other languages further away from my goals, the same pattern appeared: even if I give up on some or many of my goals, the fact remains that virtually all existing languages are designed to be fully featured, stand alone languages. Even those that bill themselves are way to featureful. For example I found descriptions similar to “designed for scripting applications!” followed by “includes a networking library, a thread library, filesystem abstractions, etc”.
Why? What would be so bad about just implementing one of these languages (ignoring my goals)? After all, these scripts are just users running their code in their computers, so if they want to open a network connection and write things to disk, it’s their decisions Well, no. Another goal for adding scripting in the game is to bring that scripting to the same level of support as mods. Mods are distributed in the Workshop. If I go and add say Lua, and make it possible to have Lua code in mods, there’s suddenly a huge security issue. I then need to become a Lua Cop and add sandboxing, and custom script wrappers and I still will get it wrong at some point (I would not pick Lua, ever, btw. If you consider Lua please instead consider Luau from the developers of a little known, small game called Roblox. They’ve already fought all of those battles for you!)
So a new goal emerged:
- It should not be possible to do anything but scripting a specific set of simulation events of the game called Nimby Rails, using the provided APIs for doing so. It is impressive some dude wrote an entire web browser in 3 afternoons using language XYZ but this is not a plus for my selection, it is a minus.
At this point my goals made it impossible to pick any existing language. I already knew that when I started the search, but this last realization solidified it.
I had to design and implement my own language. I was not worried about most of the goals. As I mentioned earlier, TinyCC was covering most of them for me. TinyCC is a huge achievement and Fabrice Bellard is a wizard for creating it. But there was one goal in particular that was worrying me a lot: memory safety. Thus I started an agonic six week period where I was designing some strategy and trying to come up with a workable idea of an implementation. I have thousands of lines long document with all of these designs. All of them, except the last, were too flawed and/or too hard, but it was a path I needed to walk.
If, as I implied earlier, I don’t want garbage collection and I don’t want reference counting, what memory safety strategy is left? Turns out a lot is left, see for example this post by the Vale developer. This post and other linked from them introduced me to a series of awesome projects and ideas. Here’s the main ones:
- The Vale languge itself, and accompanying blog posts by its main developer.
- The concepts of linear resource management. I was already familiar with Rust, whose combination of move semantics and moved-from invalidation of variables more or less puts it in a similar design space. This lead me to Austral. I really liked Austral because it was the first time I saw a borrow checking design that was not Rust, and studying it helped me to understand lifetimes and borrowing in general a lot better.
- The Hylo language and the Mutable Value Semantics paper. One of the Austral developers posted a very good overview of the idea of second class references which underpins Hylo and MVS. This is yet another example of borrow checking, but it is much simpler than Rust’s, and a lot more approachable to implement (but it precludes some programming techniques needed for implementing performant data structures in a way Rust would still allow, for example).
After reading about Hylo and MVS I decided to focus on a borrow system inspired by them. In particular I was (for now) only interested in the reference semantics, not in the linear memory management. This partly unstuck me and I made some progress in my test designs. After writing down half a dozen ways of how to implement it, I realized I needed to just do it.
To be clear, while these weeks passed, NimbyScript already existed and it was capable of compiling useful programs, including C++ interop with pointers and references. It just lacked any safety and memory protection over those pointers. It would happily read from invalid pointers or call functions which invalidated them. This is because it was just using the underlying C semantics for everything. The goal was to replace the semantics over pointers in pseudo-C NimbyScript with something else. And I designed and implemented a borrow checker, and to my astonishment, it works, and it catches errors. But I’m getting a bit ahead.
What is NimbyScript exactly? (as of 2025/06/01 anyway…)
NimbyScript is a compiled, statically typed, borrow checked, special purpose language to get called from and call to C/C++. In essence it is a macro language for interacting with C/C++ APIs, and lacks some features you would find in more general purpose languages that can also interact with C/C++. Unlike those languages, NimbyScript is JIT (AOT-on-runtime for the purists) compiled to native code and is as fast as C/C++ (the NimbyScript compiler generates C code), has zero call in/out performance overhead (because NimbyScript functions ARE C functions), zero data marshalling overhead (because NimbyScript data types ARE C/C++ types, bit-identical), and takes memory safety seriously.
To be clear NimbyScript is currently quite limited in some aspects:
- No custom types of any kind, including not having aggregate types of any kind like tuples
- No vectors or collection types
- No owned memory other than word-sized variables on the stack
All of these limitations will be reviewed and lifted to some degree, but for now they helped me focus in a workable design. Even with these limitations it is possible to make non-trivial programs in their intended role.
All of the NimbyScript syntax in this post is provisional. In particular the variable declaration syntax is duplicating the type syntax because I’m resisting introducing reference operators in the language (I want NimbyScript references to be seamless all of the time, like C++ references and unlike Rust let borrows), so the reference operator is actually a kind of variable with its own keyword (this works in NimbyScript because references can only be assigned to point to something once at initialization, again like C++ references and again unlike Rust let borrows). I need to solve this syntax more elegantly and address other issues before the language is available for use.
With these disclaimers out of the way, here’s a sample of NimbyScript, reproducing the same functionality as the previous C example:
const r_stop_changed: int = 0;
const r_stop_kept: int = 1;
const r_cont_changed: int = 2;
const r_cont_kept: int = 3;
pub fn signal_stopped_serial_apply(motion: &mut Motion, s: &Signal) -> mut int {
var changed_destination = Motion_Extrapolate_signals_try_change_destination(s, false);
if !Motion_Extrapolate_serial_reservation_fast_check(s.id) {
if changed_destination {
return r_stop_changed;
}
return r_stop_kept;
}
Motion_Extrapolate_serial_reservation_reserve_full(s.id);
if ref mut drive = motion.drive.test_deref_optional_Drive() {
drive.waiting_signal_id = 0;
drive.waiting_signal_last_check = 0;
}
if changed_destination {
return r_cont_changed;
}
return r_cont_kept;
}
pub fn signal_moving_full_apply(motion: &mut Motion, s: &Signal) -> mut int {
var changed_destination = Motion_Extrapolate_signals_try_change_destination(s, false);
if !Motion_Extrapolate_serial_reservation_fast_check(s.id) {
if ref mut drive = motion.drive.test_deref_optional_Drive() {
drive.waiting_signal_id = s.id;
drive.waiting_signal_last_check = 0;
}
if changed_destination {
return r_stop_changed;
}
return r_stop_kept;
}
Motion_Extrapolate_serial_reservation_reserve_full(s.id);
if ref mut drive = motion.drive.test_deref_optional_Drive() {
drive.waiting_signal_id = 0;
drive.waiting_signal_last_check = 0;
}
if changed_destination {
return r_cont_changed;
}
return r_cont_kept;
}
I will now go over some specifics of what I think makes NimbyScript different from your usual C-derived language.
Borrow checking: shared-xor-mutable
The core idea of borrow checking in NimbyScript is this: if at one point in the program there exists an accessible writable reference to a memory location, it should be the only reference to said memory location in the program, of any kind. If at one point in the program there are no accessible writable references to a memory location, unlimited read references can point to said location at that point in the program.
This rule, combined with an additional rule to define the ownership of values (which NimbyScript does not feature at the moment), is also called lexical lifetimes. It is the much simpler (and more restrictive) precursor of non-lexical lifetimes as featured in Rust (this post is a good explanation of the differences: https://stackoverflow.com/a/50253558).
To these rules, I decided to add an additional rule, to further simplify the system, both for myself and for players: if a reference is accessible at some point in the program, it is valid at that point in the program. This mirrors the, ahem, ideal case of C++ references, and it is unlike Rust let borrows. In particular this means there is no moved-from state in NimbyScript, for now. And finally, NimbyScript references cannot be reassigned to a different reference, again unlike Rust let borrows, and again like C++ references. These two rules make the language much simpler.
NimbyScript has borrows with lexical lifetimes. This means this is not valid NimbyScript:
var mut v = 1;
ref r = v;
Because there’s 2 paths that lead to the same memory location (v, owning it, and r, storing its address). This is also enforced for parameters (see my earlier disclaimer for the redundant type syntaxes in the current prototype):
fn f(r: &mut int) {
ref r2 = r;
}
A special mention is required for the case of calling functions with reference parameters:
fn f(r: &mut int, r2: &mut int) { ... }
...
var mut v = 1;
f(v, v); // this is invalid code
var mut v2 = 1;
f(v, v2); // this is valid code
...
The first f() call is trying to borrow v twice, so this is an error. The second call uses different values for the arguments, so it is allowed.
If you followed along, you might now have a question: how passing a reference to v, even in the valid case, is allowed? That means there’s both v and the reference to the same memory! Yes, that’s true, but remember the rule: accessible writable reference. The caller of f() cannot access the created reference for the argument. And f cannot access the v variable. Therefore the rule holds up.
In fact the act of hiding something to be able to access it in a different way is useful enough that, copying Hylo, I’ve introduced a syntax just for that:
var mut v = 1;
borrow ref r1 = v {
// v is now hidden inside the borrow {}
// these next 4 lines are valid
ref r2 = r1;
ref r3 = r1;
ref r4 = r1;
ref r5 = r1;
// this one is not! v is hidden inside the borrow scope
v = v + 1;
}
// v is usable again here, and the r1-5 references are out of scope and disappeared
The borrow keyword precedes a reference variable declaration, and in exchange of hiding every variable and reference on the right of the equals sign, it allows to bend the rules. Basically if something would work as a function argument, it will work as a borrow variable.
More implicit borrows: pointers are nullable references
Check the earlier signal control example. Where are the borrows? There’s none! Yet a lot of borrowing is going on in that example. This is another point where NimbyScript and Rust diverge, and NimbyScript resembles Hylo more: borrowing is most of the time automatic.
A particular interesting feature of that example is these lines:
if ref mut drive = motion.drive.test_deref_optional_Drive() {
drive.waiting_signal_id = 0;
drive.waiting_signal_last_check = 0;
}
This is inspired by the if-let syntax of Rust, and if (auto =...) of modern C++. The horribly and very temporarily named test_deref_optional_Drive method returns a *mut Drive pointer. Pointers exist in NimbyScript, but they are very different from C pointers. I basically hijacked the name to introduce nullable references. But… nulls?! In this Rust wannabe which cares so much about not crashing? This is possible because NimbyScript pointers are essentially useless. You can pass them around (always with the same rules as references), but you can’t do anything else with then except test and transform them into a regular reference if non-null. That’s what these 3 lines of code are doing: the function returns *mut Drive, which might be null or not, and the body of the if only executes when the return of the function is non null. The drive reference is also pointing into this guaranteed valid memory. And by the way, you cannot access motion inside this if body. It is hidden because it’s at the right of the equals. This is a very good thing, because otherwise you could call some motion.drive.test_reset_optional_Drive() and make drive point to invalid memory while it is an active reference. This idiom is another example of an implicit borrow making it impossible to write dangerous code.
I could write a lot more about this system and NimbyScript as a whole, but this post is too huge already. Its current status goes well beyond what is presented here and so far I am very encouraged at how well it is progressing as I add more features. It feels very natural because it’s also the way I’ve been programming C++ for years, with strict separation of mutable vs non mutable access and minimizing sharing.
There’s still a huge amount of work left for NimbyScript to be usable as the NIMBY Rails scripting language, but it has made huge strides in the past two months, from “okay I have a backend and a bunch of ideas” to “it runs and does useful work, while hitting on all the goals”. Before a game version with NimbyScript is released it still needs to tackle some huge problems, like memory ownership of anything larger than a machine word, collections, and at least rudimentary custom types. But at least now I am convinced this is doable, in the way I wanted to do it.