NIMBY Rails — A development retrospective
My new game, NIMBY Rails, is now public. I’ve been working on it for the past 18 months and I kept a development diary. Here’s an abridged version.
It all started with a tweet
I saw @paniq tweet about paper which involved a very smooth, very natural curve interpolation, and I was immediately intrigued. To me it looked like a series of circle arcs linked by line segments at their tangents, and I quickly produced a bézier approximation of the same idea, drawing the arcs using cubic béziers with the often used coefficient of 0.55191502449.
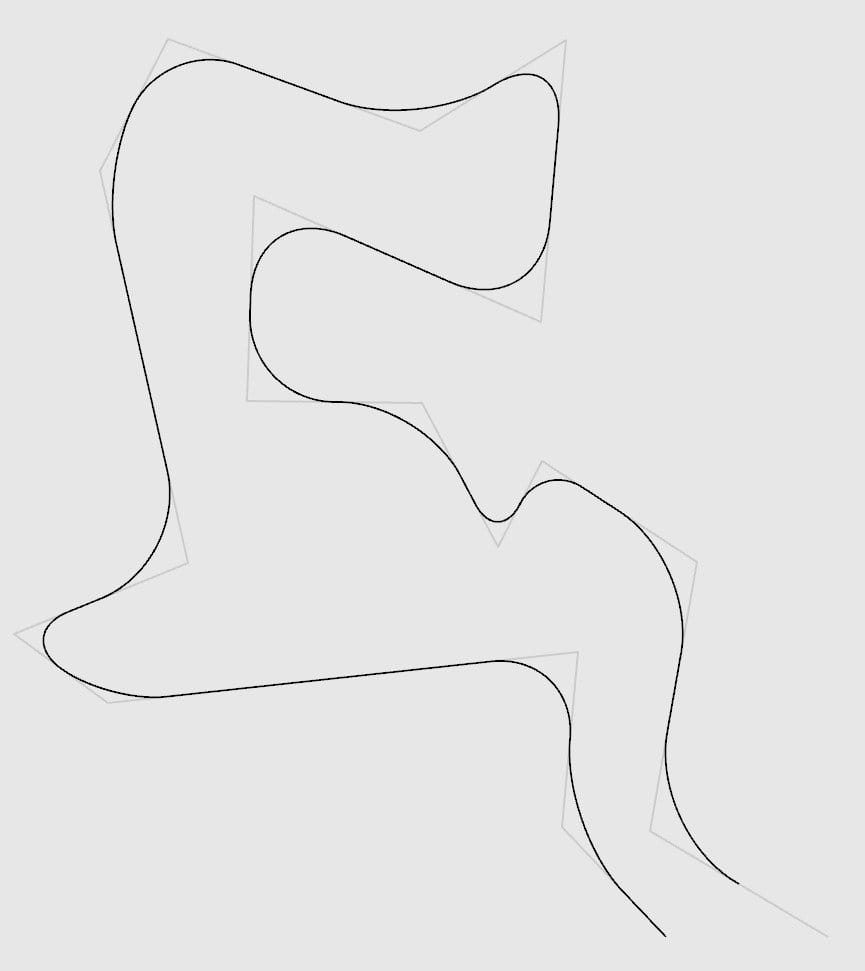
I also had been, for some time, thinking about doing a game about railroads, with the twist of making it based on real world maps, trying to approximate real track networks. But the various games I tried that had vector-based tracks had either a too complicated interface for laying them, or tried to simplify too much and the curves seemed unnatural and quite different from real world track layouts. I was truly enamored with this way of smoothly interpolating a polyline into a curve, which was new to me, and seemed much more usable than the splines I knew. The idea of doing the railroad game with a track design based on this line interpolation started taking shape. So, barely a month before my finals, I started working on the idea for way too many hours every day.
November-December 2018 — I hope you like maps
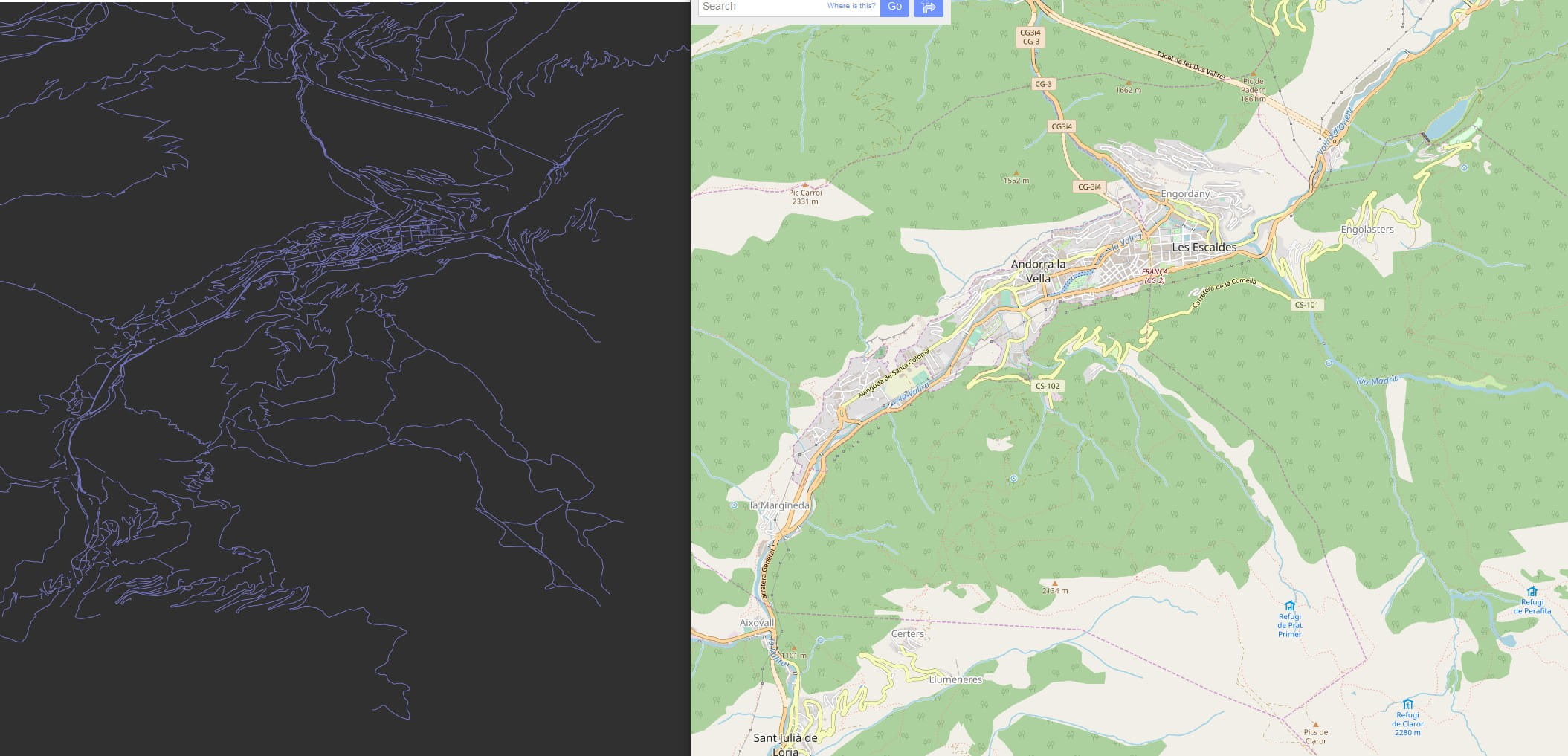
I mentioned real world maps earlier. I really wanted to have the real world maps as the map of my game, the canvas for the player to build their track networks, but doing so would require using actual GIS data. The obvious place to start was OpenStreetMap. I like programming way too much for my own good sometimes, so I decided to start from raw OSM PBF dump files. These contain an optimized protobuffer dump of the OSM database, and can be found already pre-cut down into countries or regions. They are not database, being more like a serialization of the OSM data. In particular they lack any indexing. My idea was to load these PBF files and transform them into my own database format, with heavy lifting of processing ways and relations into triangulated shapes and generating indexes as a preprocessed step. I ignored MapBox, PostGIS and other ready-made solutions. My own map format would be stored as a series of tables in a SQLite database, with proper indexing.
In parallel to the OSM map preprocessor (which was alarmingly growing in complexity very fast), I started developing a map renderer. This would the prototype of my game. It calls into the underlying graphics API of the system via the excellent bgfx, and it would be all in C++, with me having been reconciled with the language after a years long detour into various Lisp dialects. This would be low level coding with no game engine and using libraries only for things like image loading.

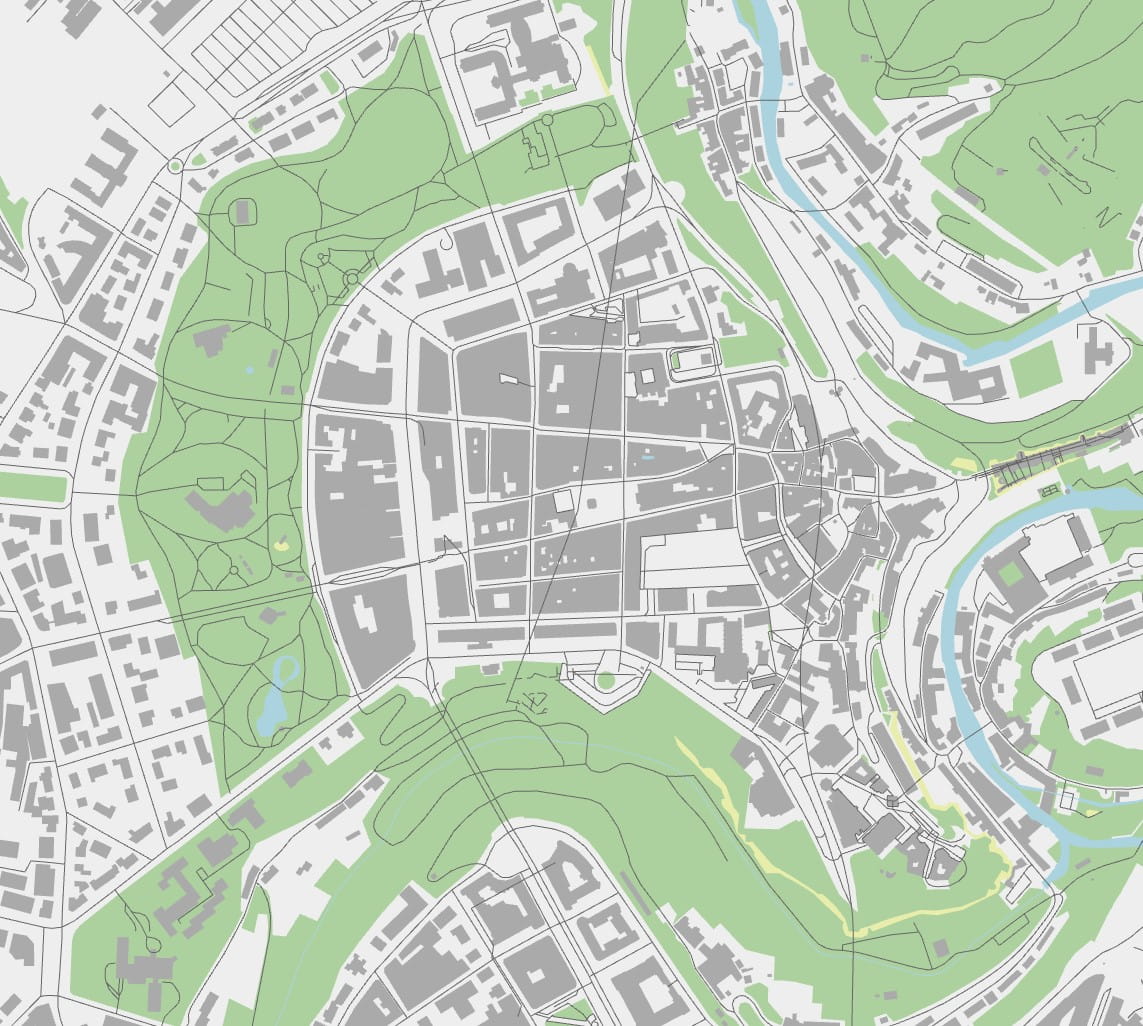
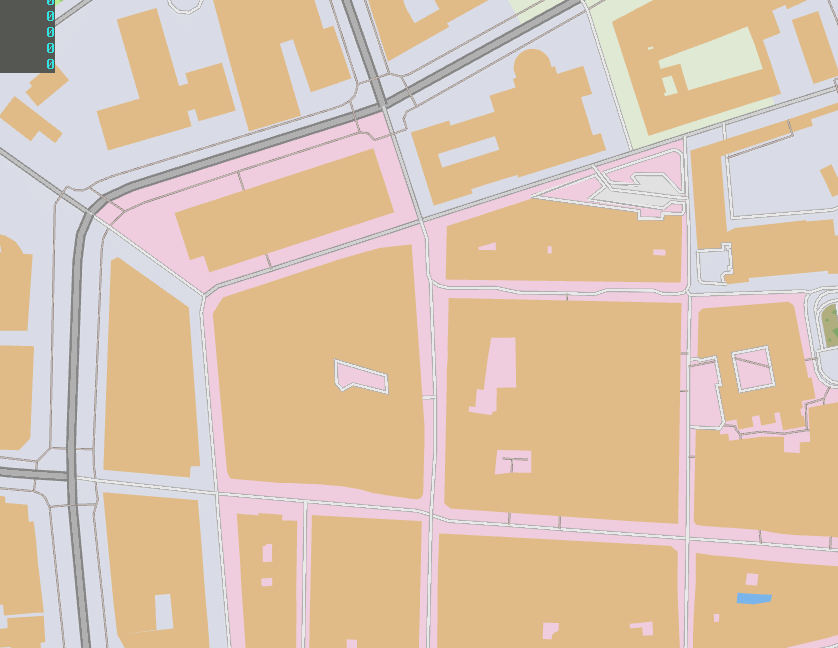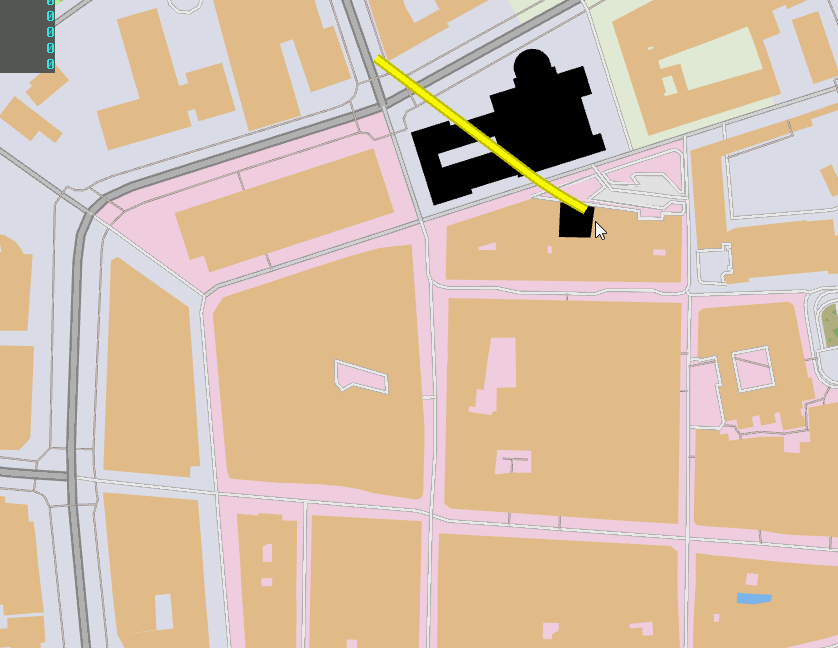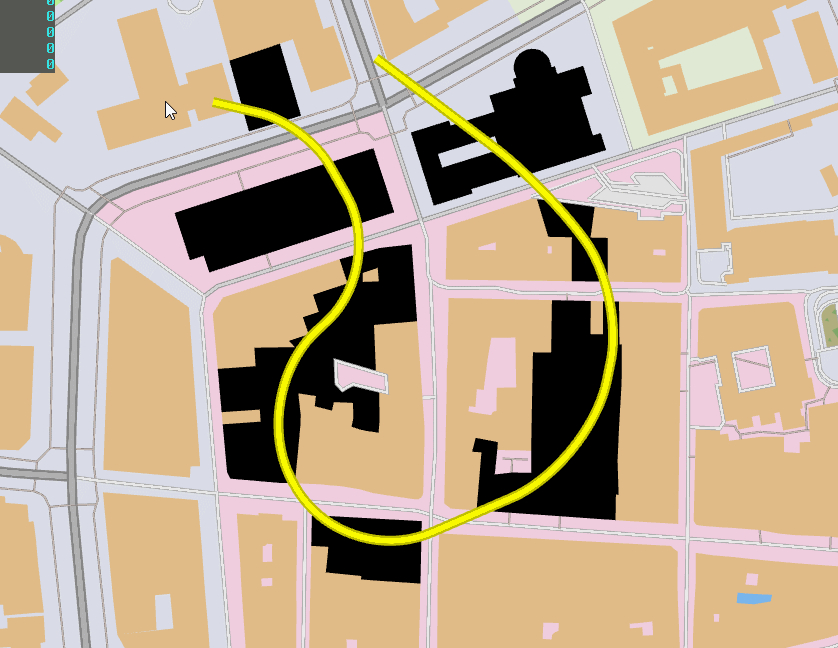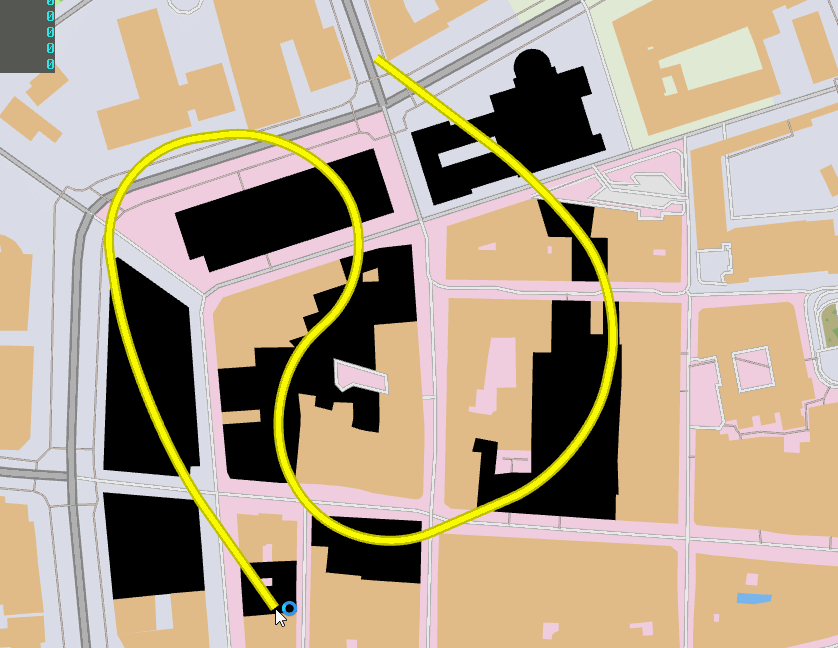
January 2019 — Track work
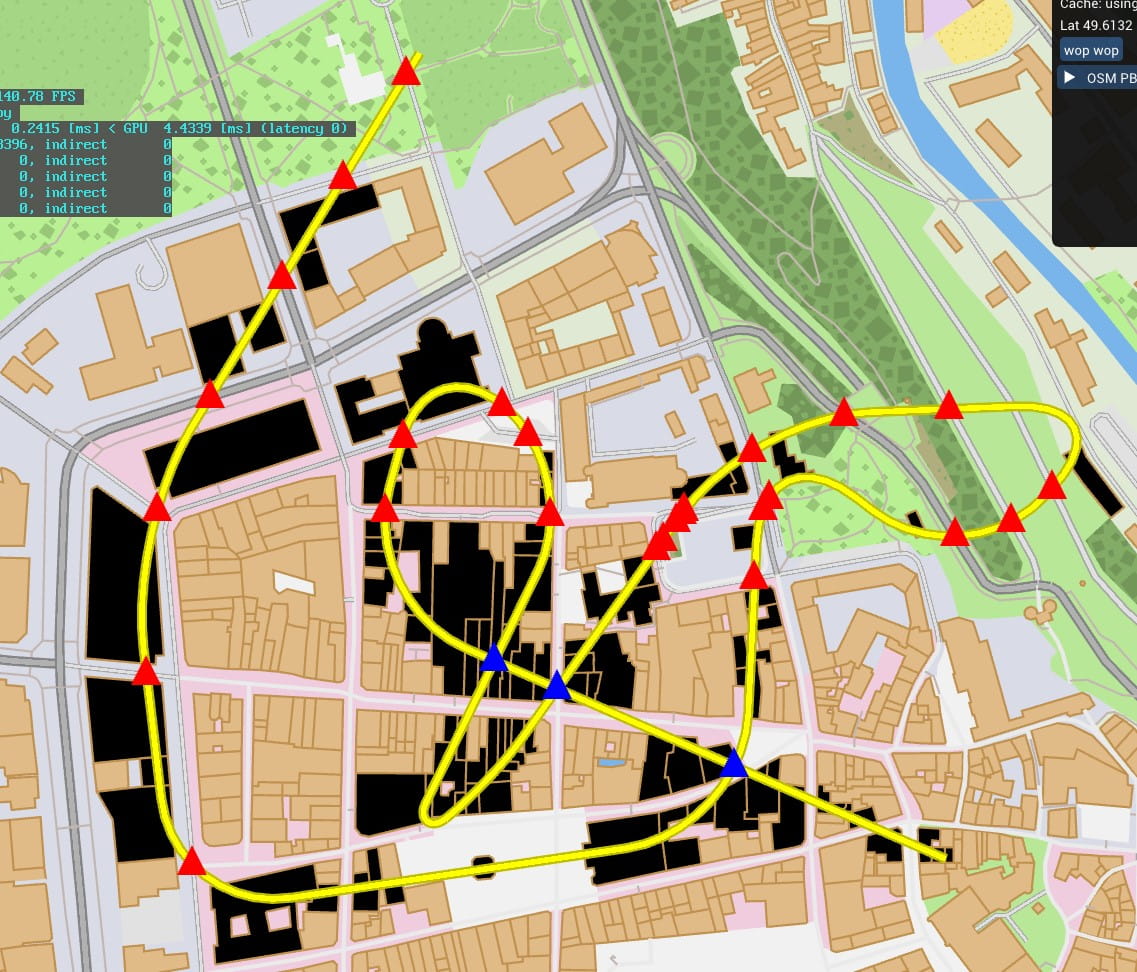
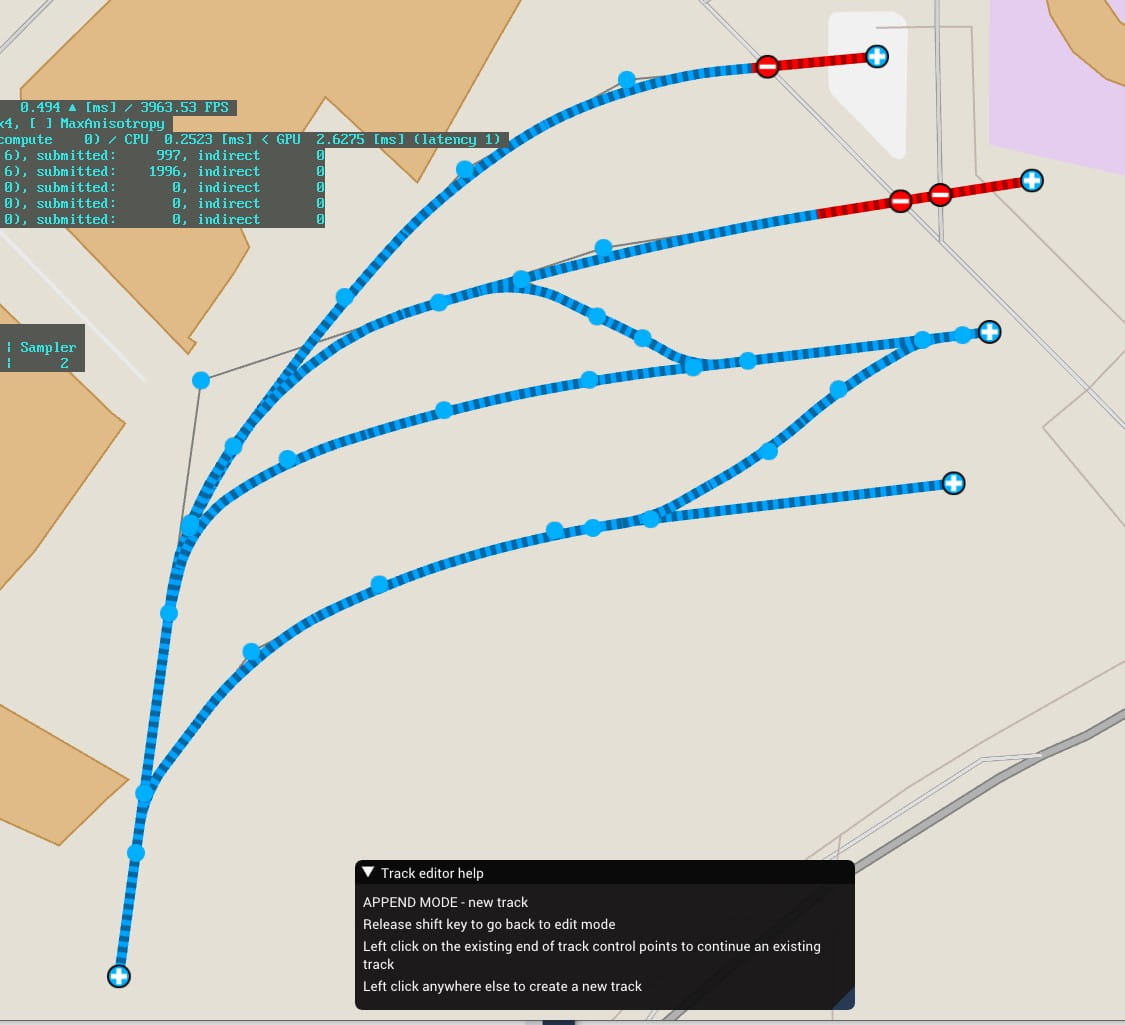
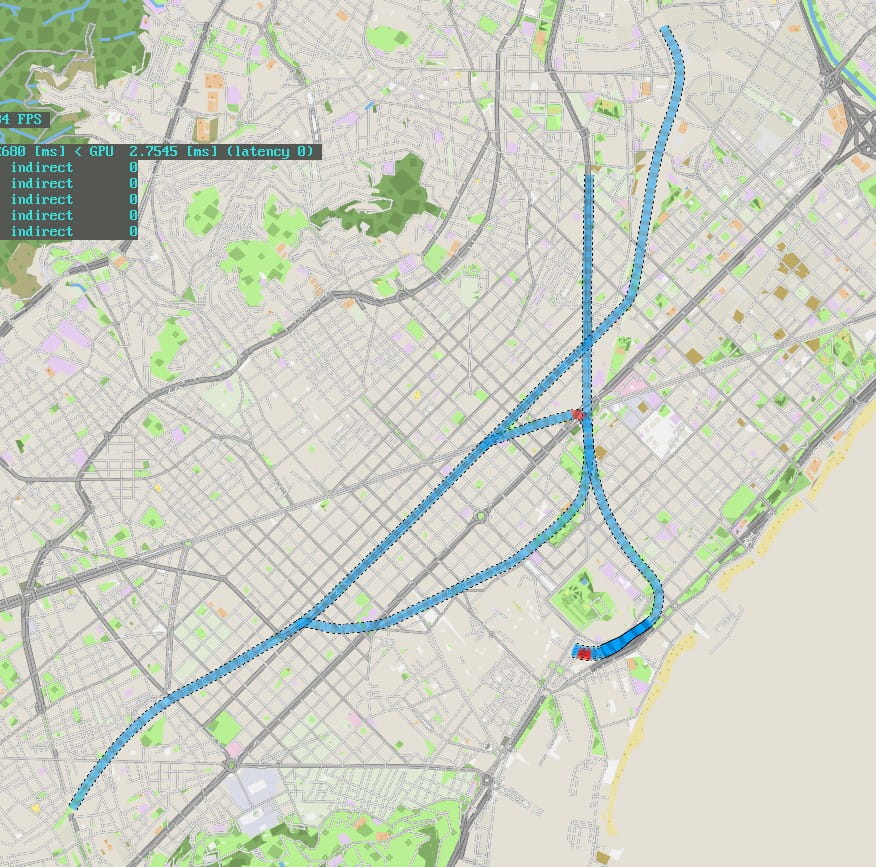
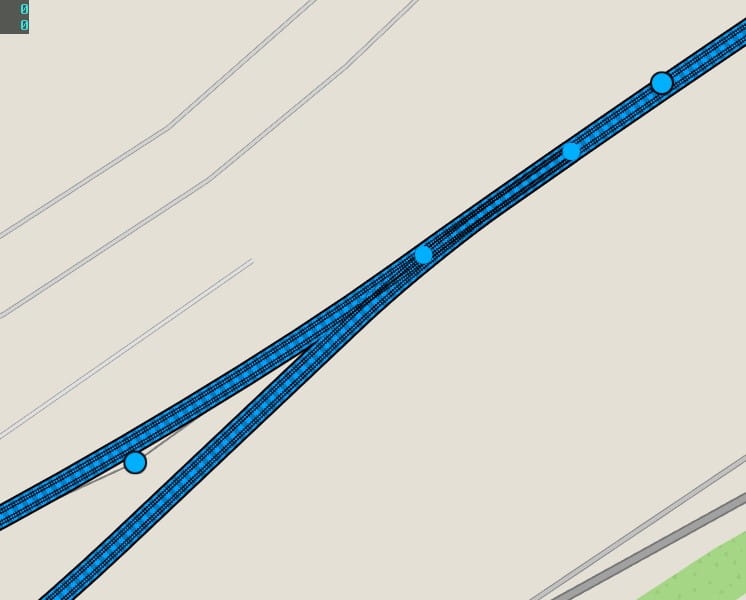

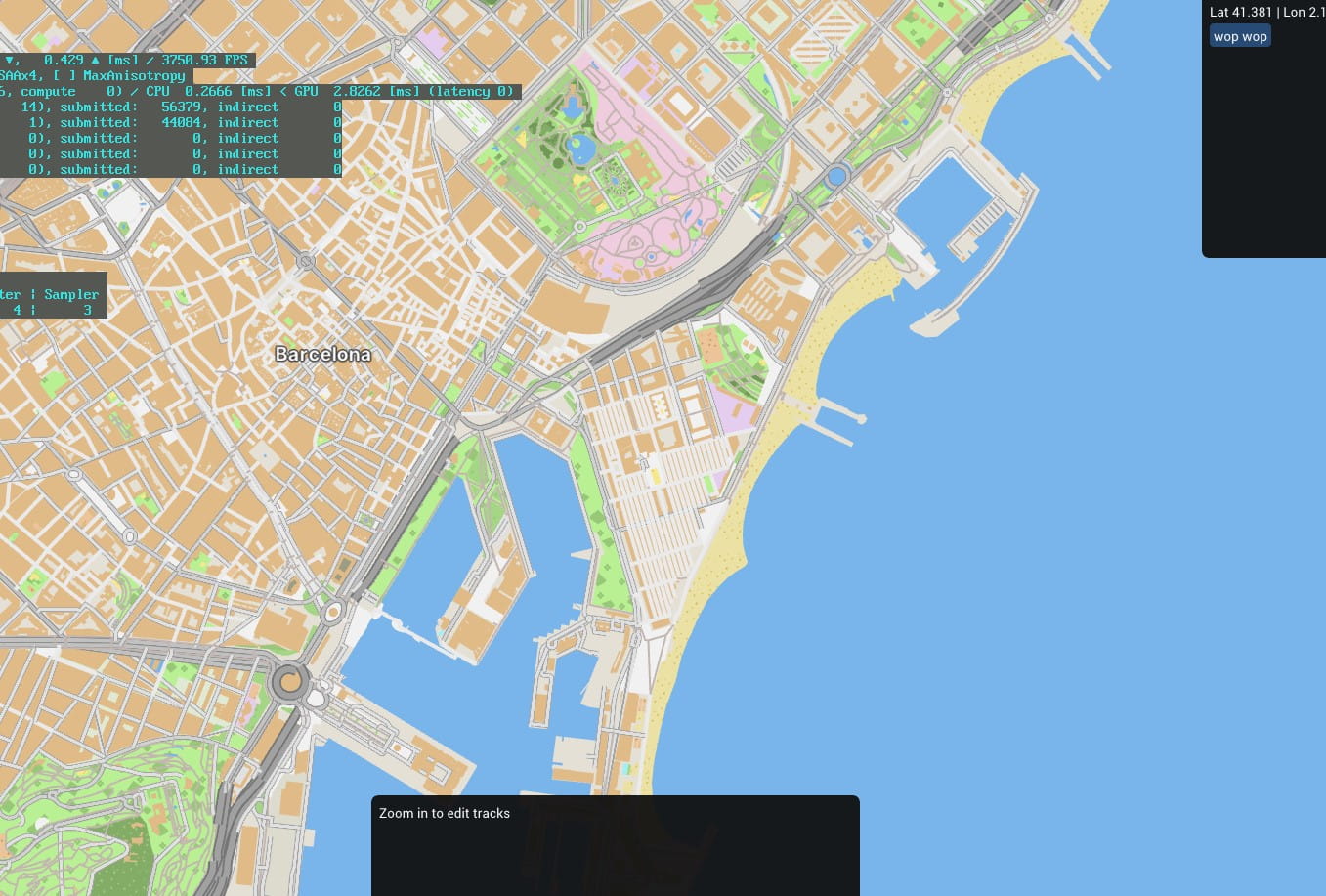
First half of 2019 — Prototype ideas and trains
I somehow managed not to fail my finals in January, but I needed to focus more on my degree, so I didn’t devote so much time to the game at this point. I mostly hacked on an idea for multiplayer and managed to get it working, but it still needs a lot of work. It helped me to clean up the data model code a lot, as the later work on the editor undo stack did, and I now have plenty of design notes for a proper new data model that will support multiplayer, full undo/redo stacks, forward compatible saves, potential for parallel simulation code, and all the other goodies that come from being able to express your game state in terms of immutable, copy-able state plus discrete transactions you can apply or rollback at will.
What is a rails game without trains? There had to be trains! A first prototype dealt with very simple entities randomly circulating in a track network. Go forward while there is track to go, bounce back when it ends, randomly pick a branch if one is available.
Pathfinding came next. The same dumb train as before is now capable of picking a random point in the track network and attempts to trace a path using the A* search algorithm. It keeps into account the track speed and the track length to pick the shortest time possible between two points.
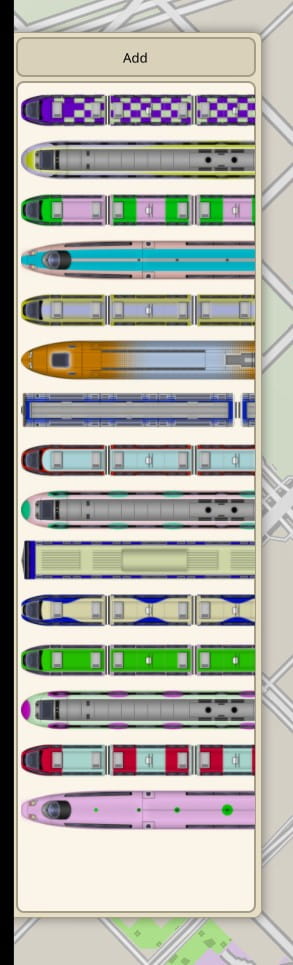
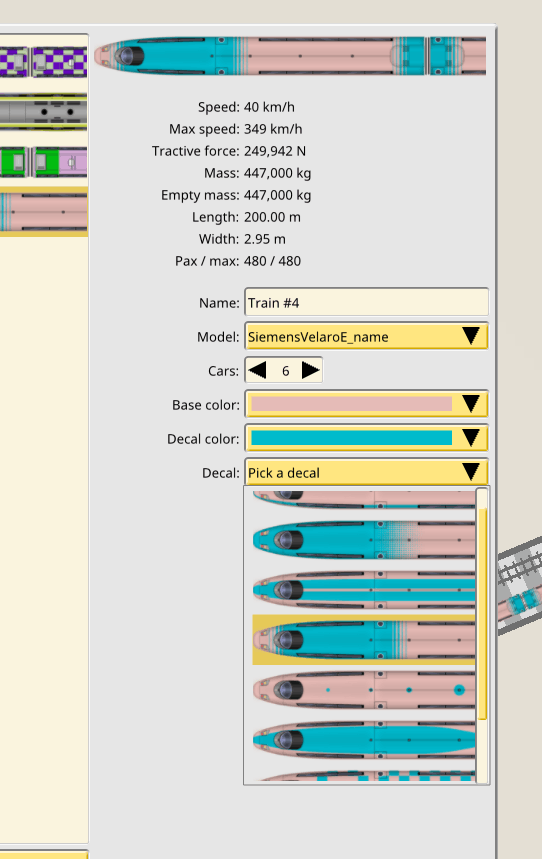
Next came making the trains look like more like trains. They are now composed of actual 1D entities which map on to segments of tracks, with several linked elements, one for each car.
At this point Max had also produced textures for the trains, with a variety of long distance, commuter and high speed models, and a full set of customizable decals for each.
Hit testing is not so straightforward as it looked like initially. While the non-branch case is an easy 1D check, the branching case requires a full 2D test. So trains are checked as 2D entities with generous bounding boxes when in the proximities of branched tracks.
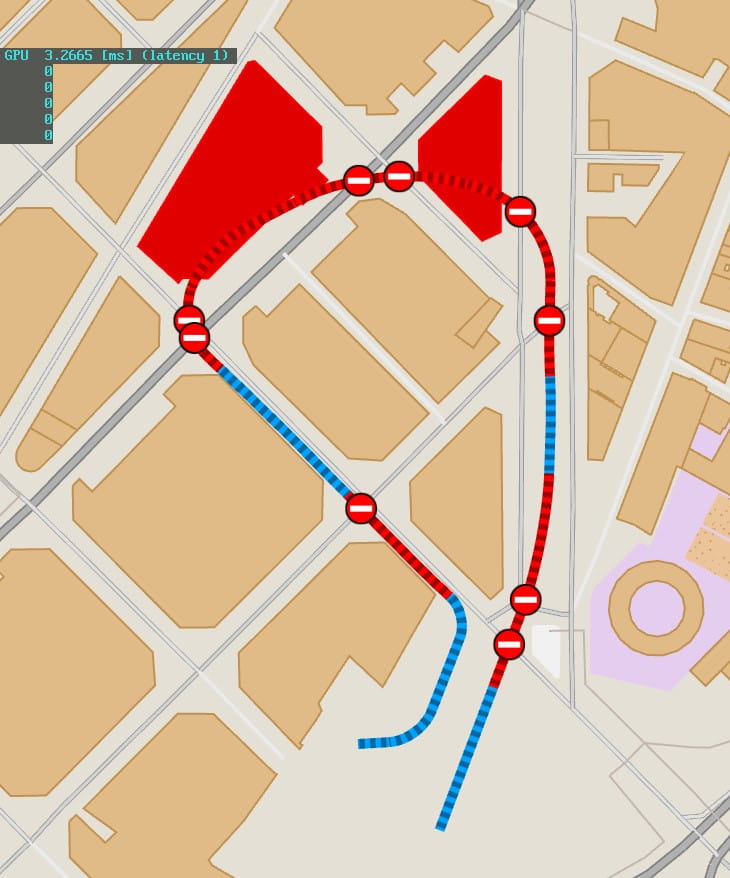
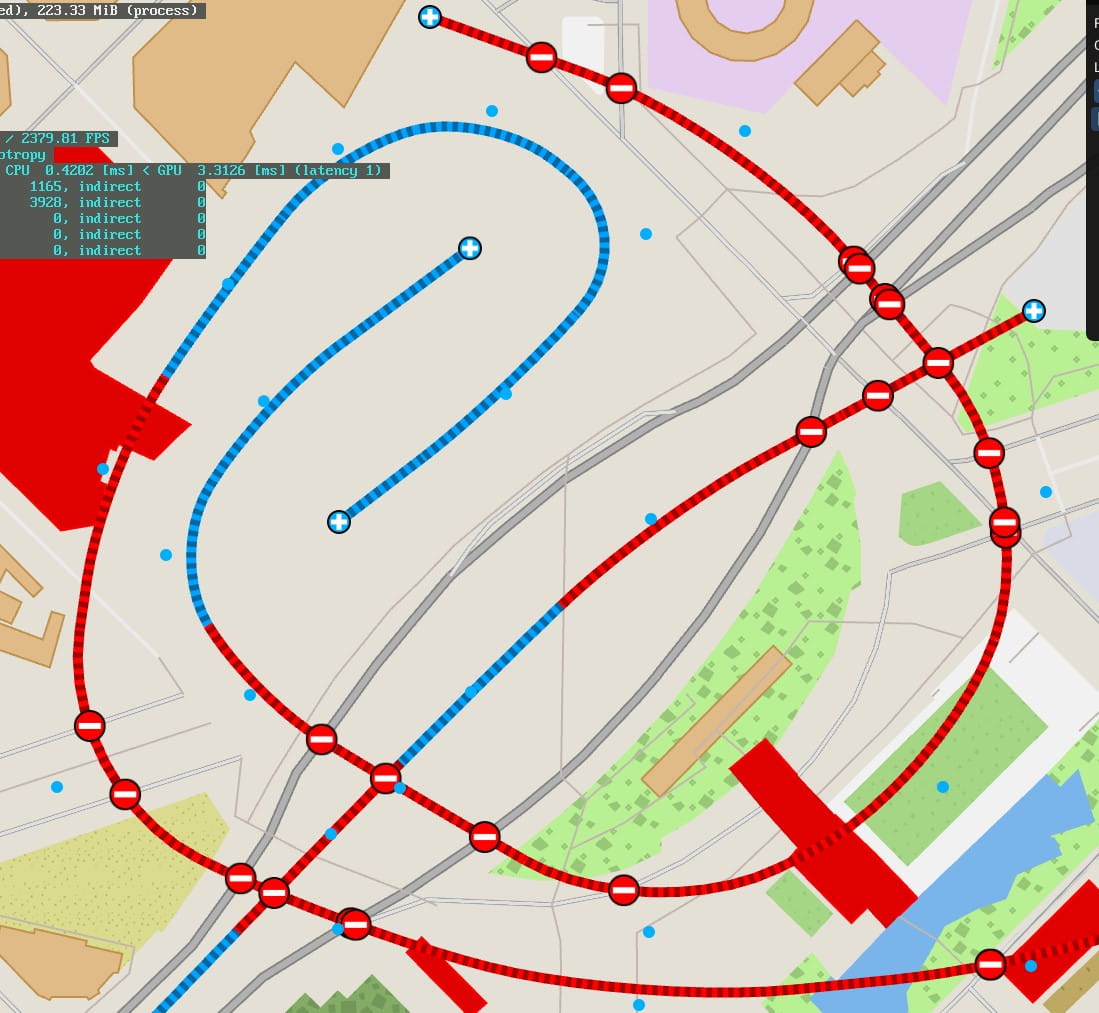
A massive rework of the map processing pipeline and data format was also started, to culminate months later in summer. The idea was to optimize as much as possible the data format for a very lofty goal. At this point I decided I needed vector tiles. I would still be able to access all the map geometry as shapes, but those would be stored inside highly compressed, delta coded, quantized tiles, per LOD-level. I needed an order of magnitude decrease in the map file sizes. Because…
June 2019 — It’s the whole world or nothing. Also I will never get hired again.
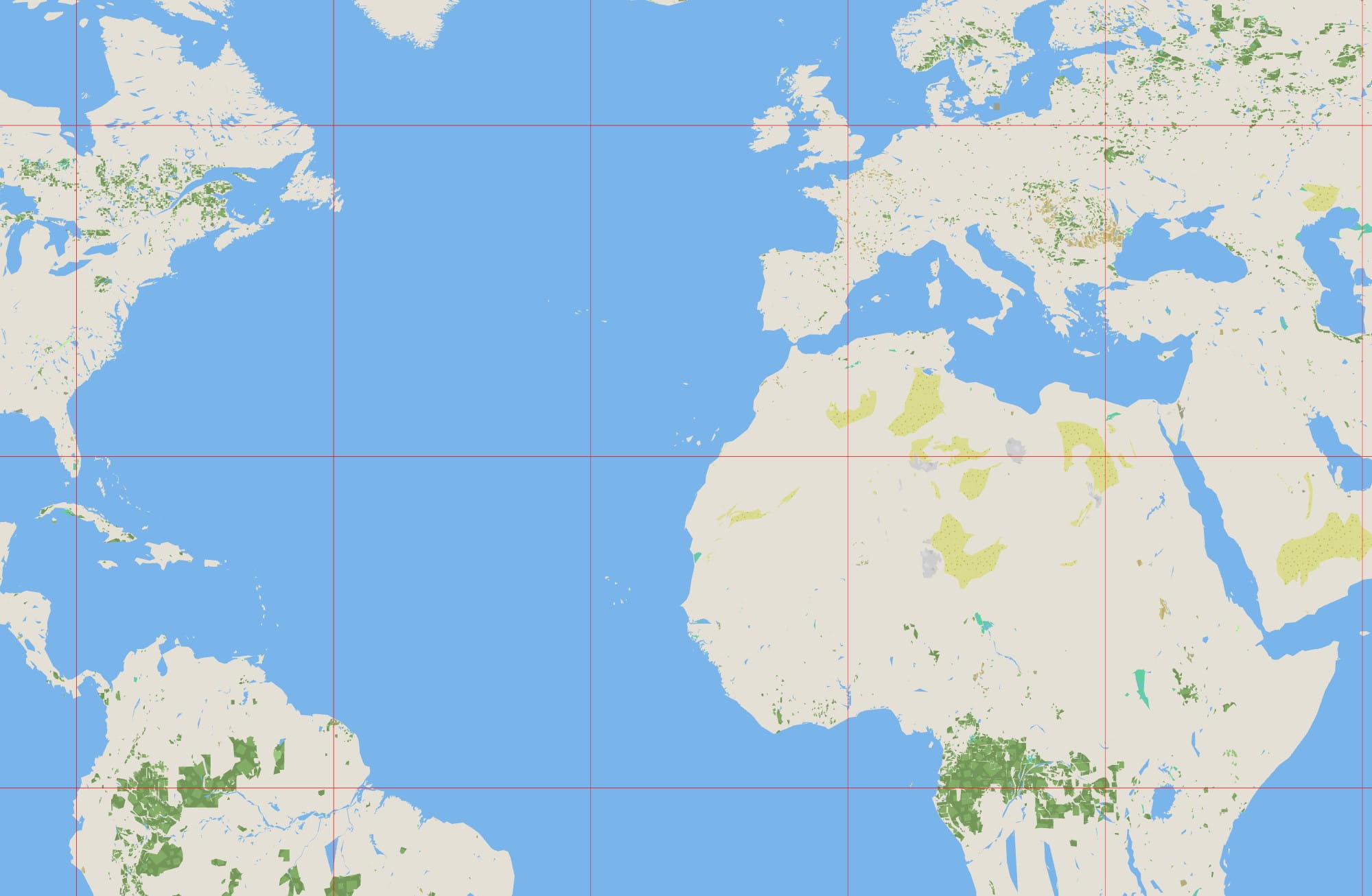
I decided I wanted to include a map of the whole world, to make the game playable offline, with as much data as possible, in 20GB or less.
And thus started the big adventure of indexing the entirety of the worldwide OSM ways and relations database, triangulating and bound finding all of it, stitching every single way and relation, and distilling this entire thing into a highly compressed, highly optimized multi LOD vector tile database for drawing in a single file at or under 20GB. Again, I ignored MapBox or any other solution, and did my own thing. And what thing it was.
It was time to throw away everything I had learned about databases and scaling. I don’t have the money for horizontal scaling and doing things “by the book”. The prospect of indexing the OSM master PBF file is straightforward enough with a RDBMS, as PostGIS and the various OSM importers show, but I wanted to do it faster and cheaper. Much faster and much cheaper.
The first step of this process is turning the OSM PBF, a linear dump of unindexed, unlinked data into an indexed, stitched, and denormalized intermediate database. I picked LMBD since its write speed is legendary and it’s basically the fastest on-disk database you can get, while still having proper indexing. This first processing step involved renting a 1.4TB of RAM cloud instance for 8 hours. Quick FAQ:
Q: What?
A: I later optimized it down to just 800GB. It needs all of that memory to first build an in-memory index of the OSM PBF file, then dump it all as fast as possible into the LMDB file, saturating the disk link.
Q: Why not just stream insert it into the LMDB file as you read from the PBF?
A: As fast as LMDB indexing is, it’s still slower than a RAM heap-based hash map, for example. This way was faster, as in hours vs days. That kind of insertion is also the reason it takes days or weeks to do this with PostGIS.
Q: You don’t know anything about databases and scaling, I would never hire you.
A: It’s much cheaper and much faster to rent a 1TB+ RAM spot instance for 6-8 hours than say a 128GB regular instance for a week, or a cluster of them because itshowsitsdone. And this wasn’t the best part of what I did that makes me un-hire-able forever, keep reading!
The second step of the process is to use the indexed OSM data to build the game map tiles database. This involves indexing all the shape and line bounds in-memory in a R-tree. And since I like fast, it also involves loading all the data in RAM.
This time I knew the process was going to be much slower because it involved real CPU wrangling rather than some light data translation. But I was still determined to not use a database. So I load the entirety of the LMDB file as plain variety of C++ structs and objects and collections of them, and work with them as just in-memory data, rather than performing reads into the database. It turned out I ended up using the LMDB file as a preprocessed step for loading the OSM data. It’s still worth it since it’s much faster than querying the database on demand, caches or not.
But I was going to be over the 24h spot instance limit this time, the CPU cost of building the tiles is too high. So I decided I was going to hit the disk. As swap. This process runs on a rock bottom priced bare metal server provided by Hetzner. I used a 32 core Threadripper with 128GB of RAM and crucially, a couple of fast NVME drives in RAID0. I set up most of the drive space as a multi-TB swap space, and I let the map processor allocate as much heap memory it needs, in excess of 1TB.
Q: The hell?
A: The swapfile is my database, you could say. Also modern C++ libraries are a wonder and it handles a 1TB heap like a boss.
Q: I vanish you and your next 20 generations from the work force forever.
A: Have fun with kubernetes and spending two months and five figures doing what I did in five days and 100 bucks, I guess.
July 2019 — Adding some raster
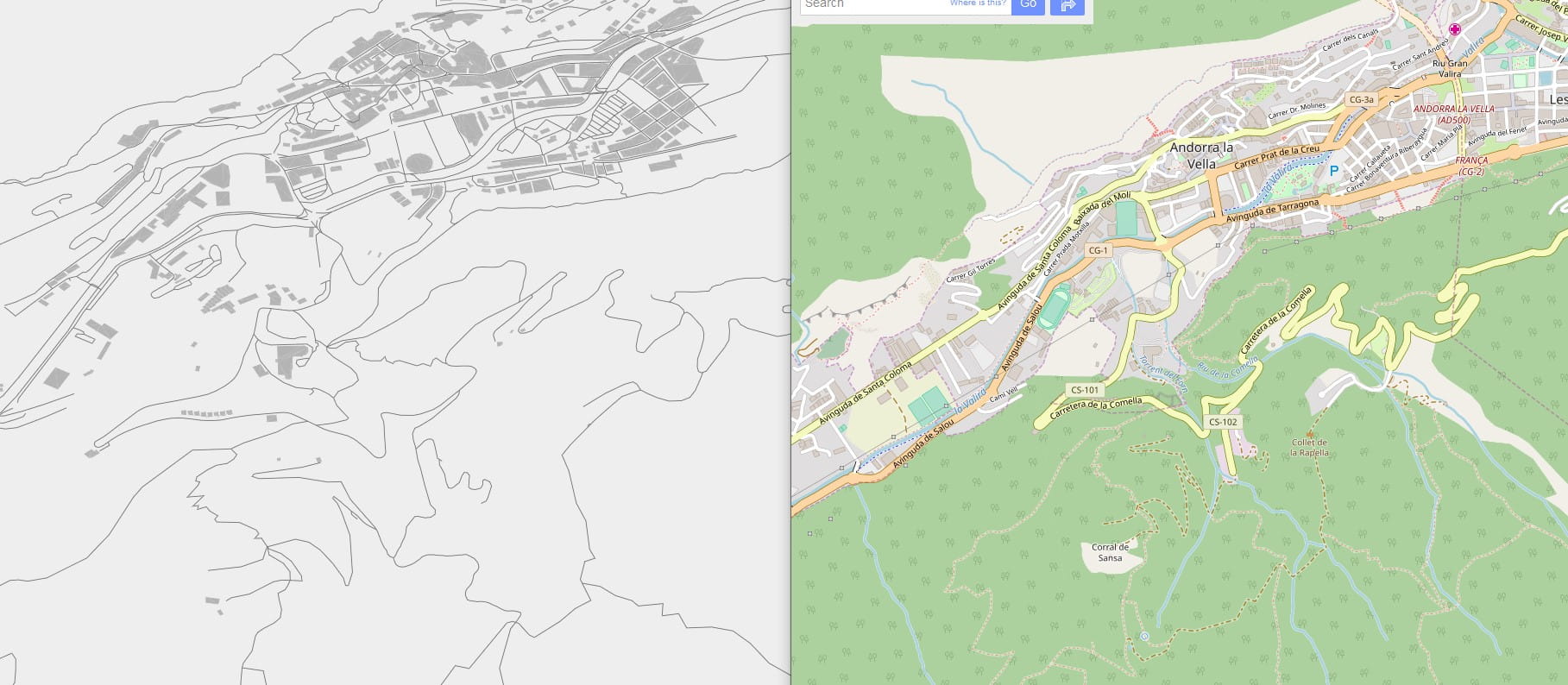
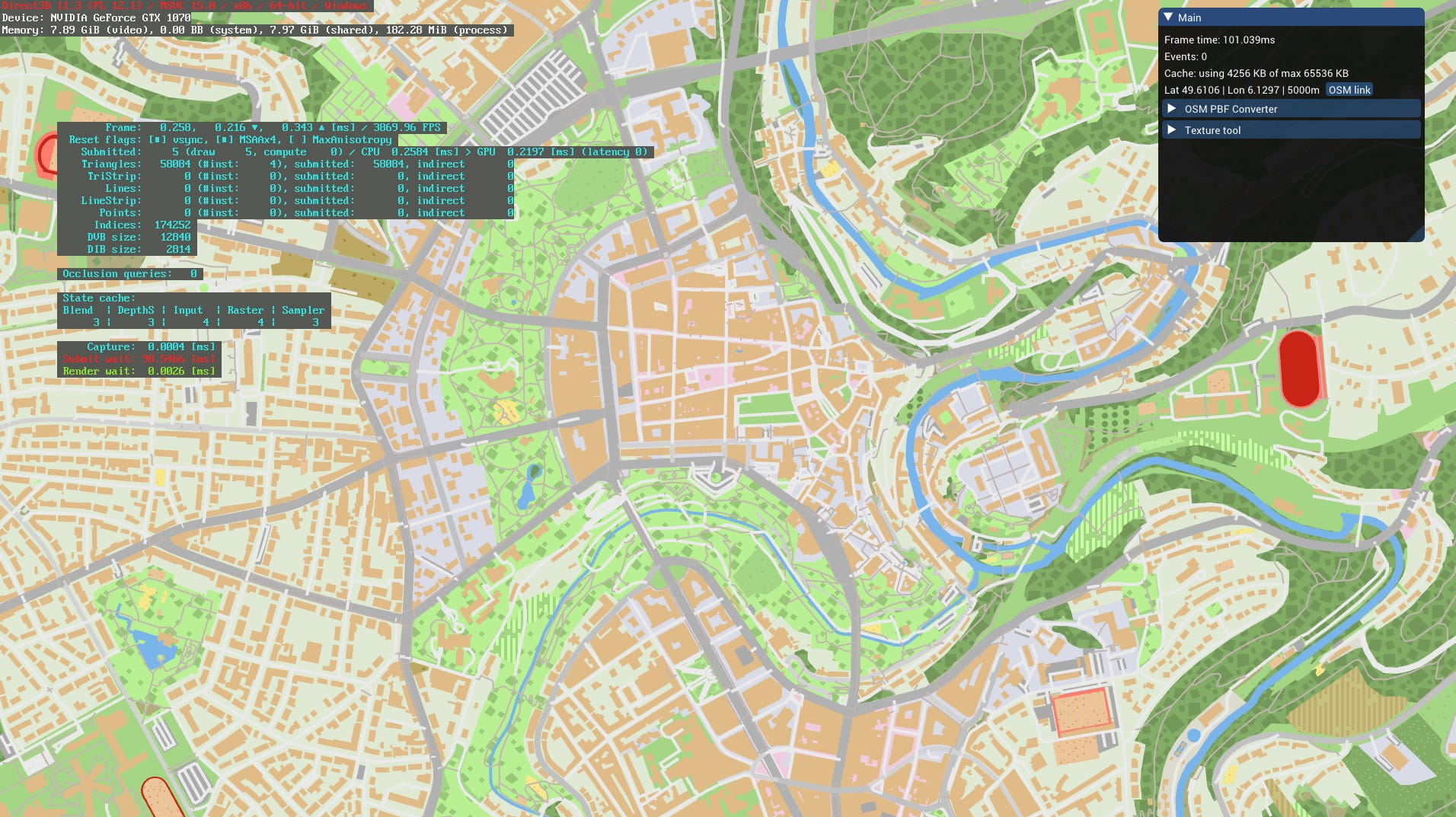
I overshot my goal of a 20GB map. The map, covering the entire world, almost every road and street in OSM, indexed and ready to draw, was now 16GB. Oooops. And it also looked very poor at lower LOD levels. The shapes were too small, the roads and rivers irrelevant at the continental scale. OSM is not a topographical map. I needed some topography to make the game look nicer at these low zoom levels, so I decided to go hunting for some elevation tiles from NASA.
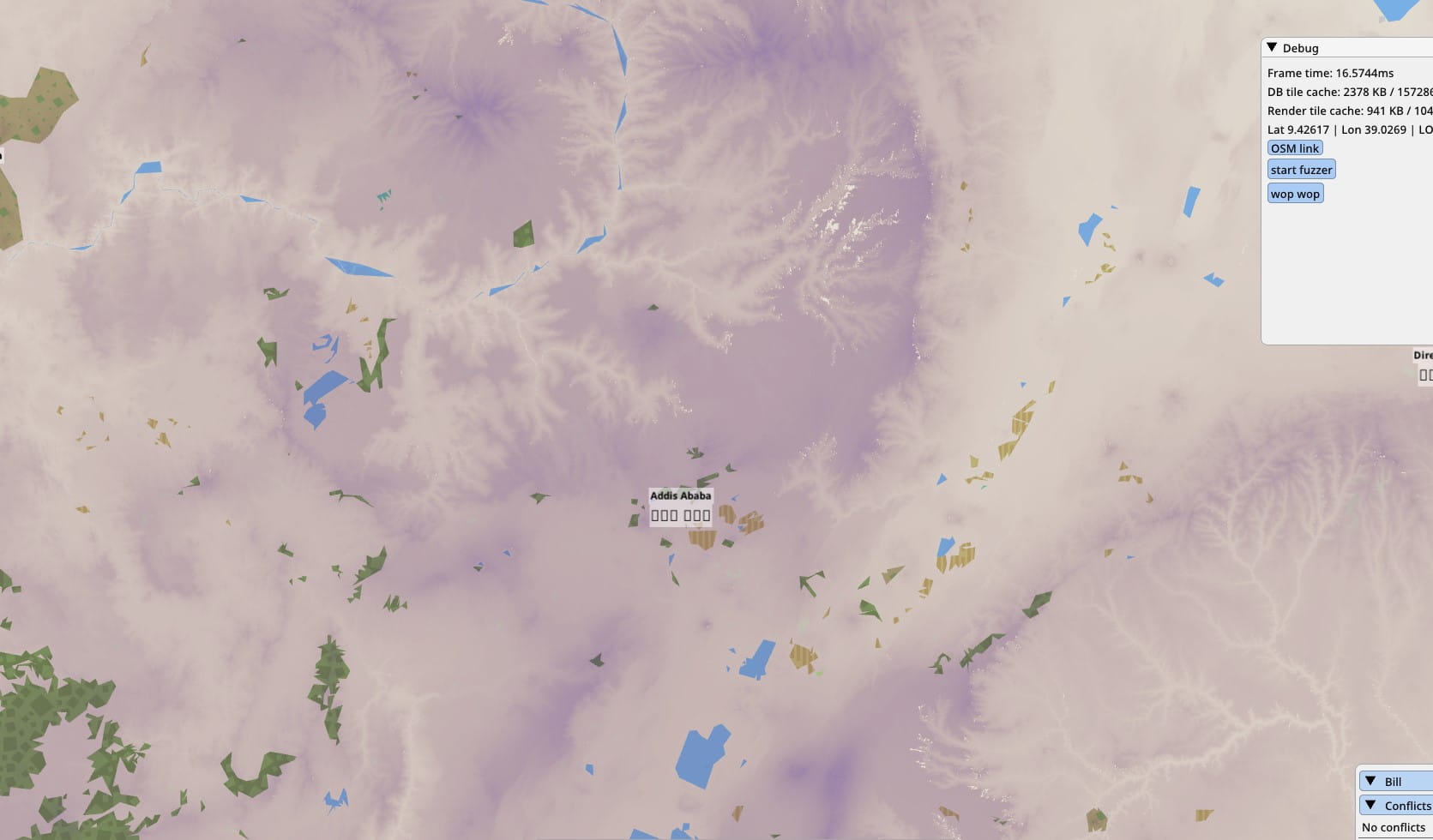
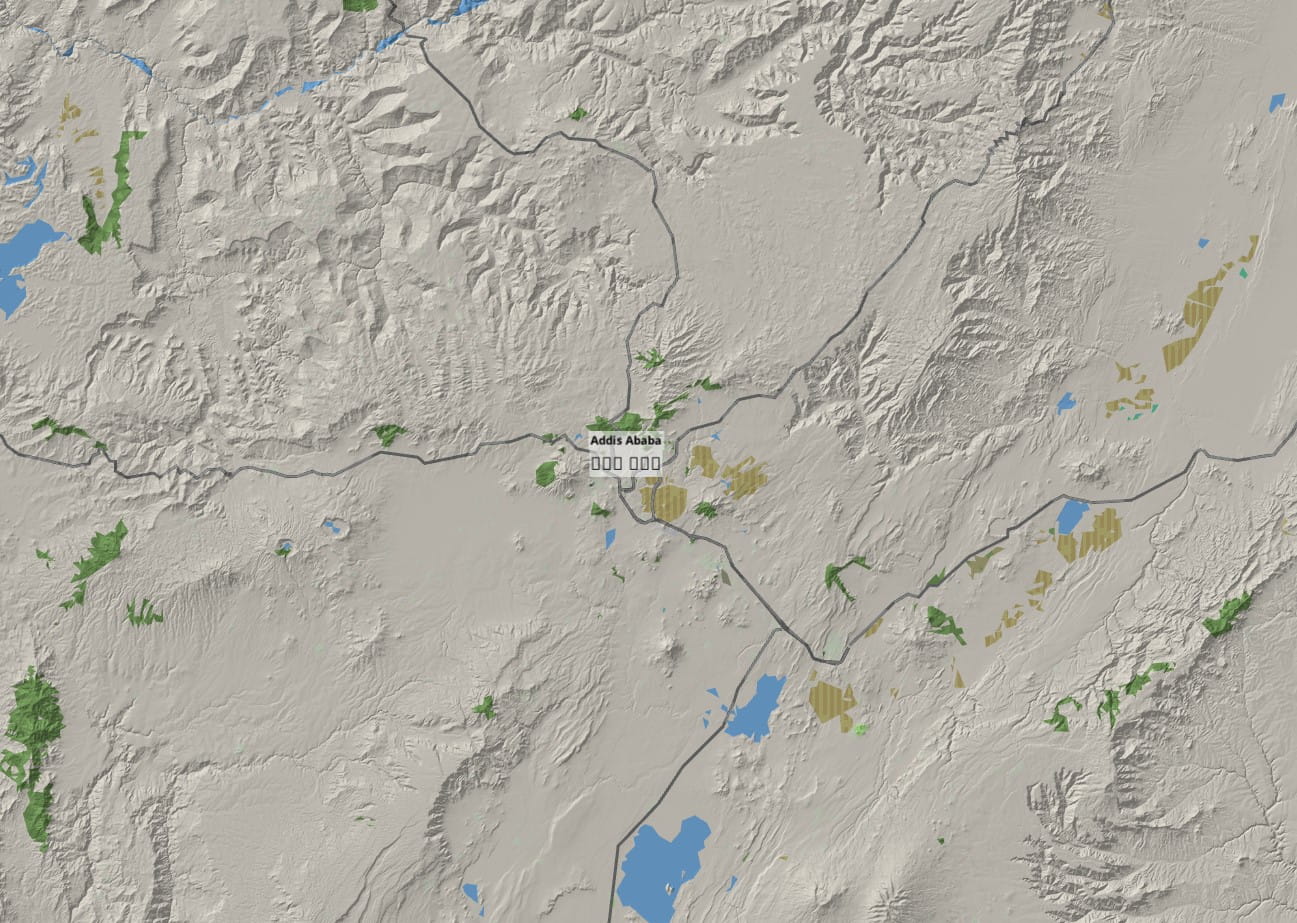
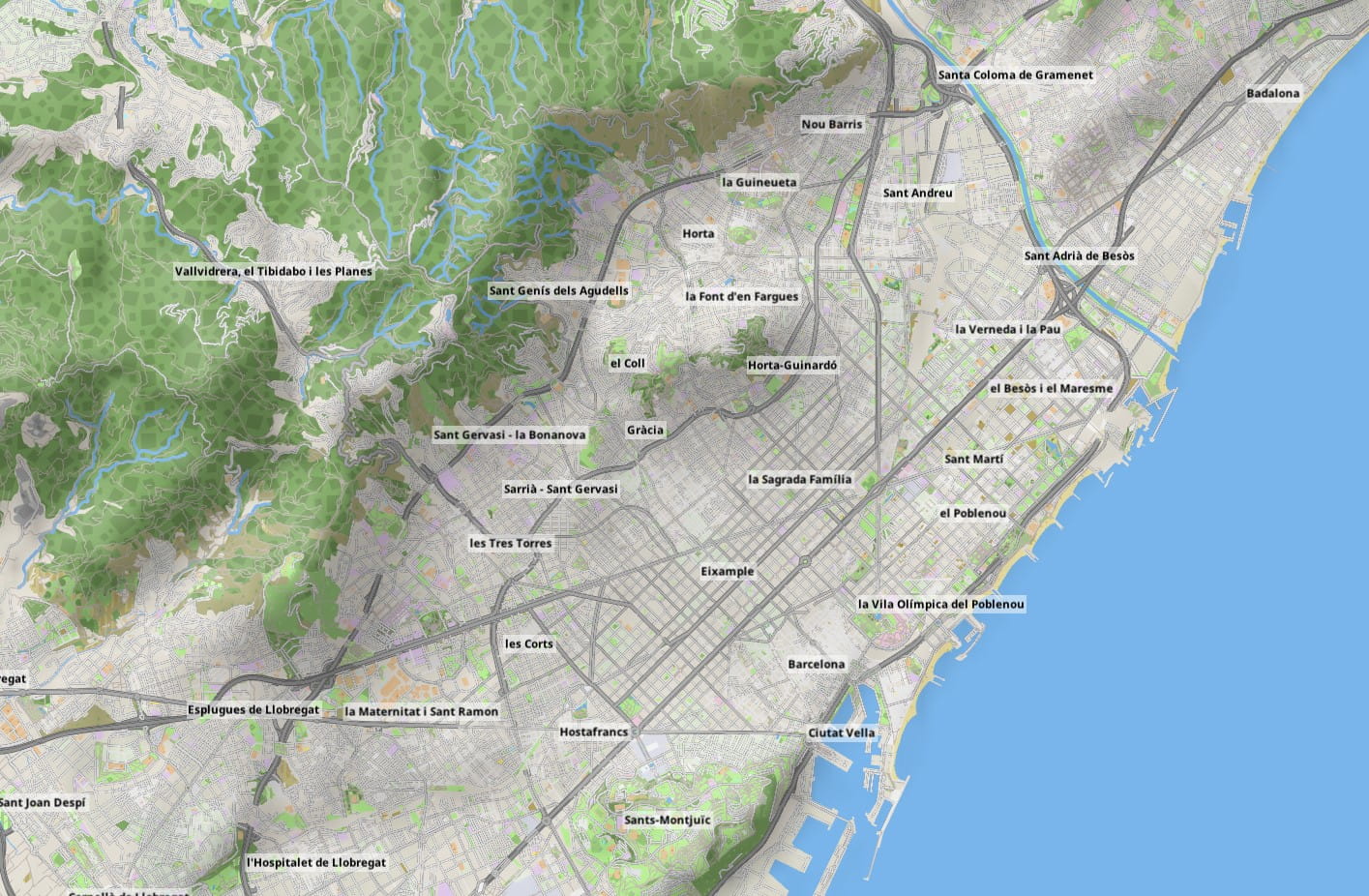
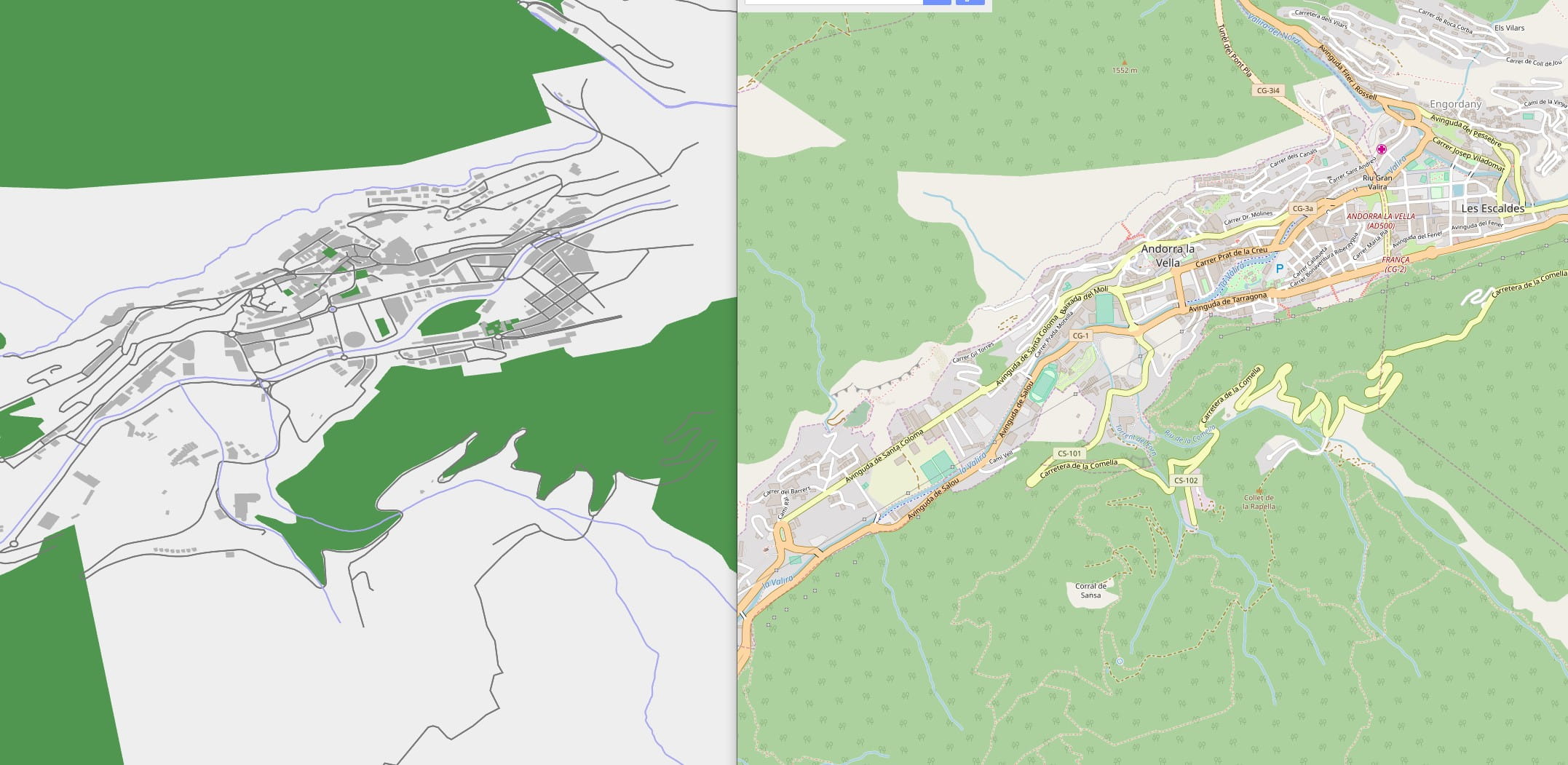
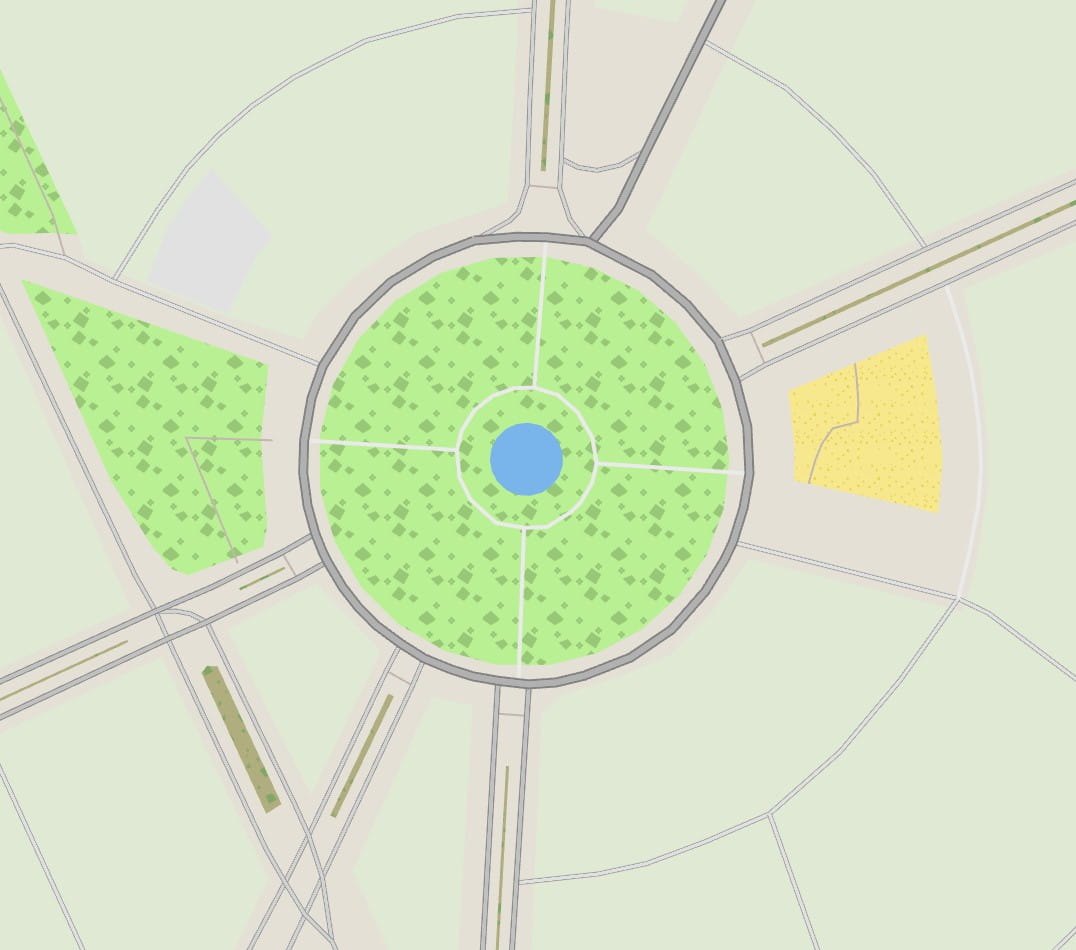
The relief mapping looks good, but it’s still a gray map. So another dataset was applied: a land usage texture provided by ESA. Again this is stored only for low and medium LODs, and progressively made transparent at higher zooms. This is the world overview without land usage:
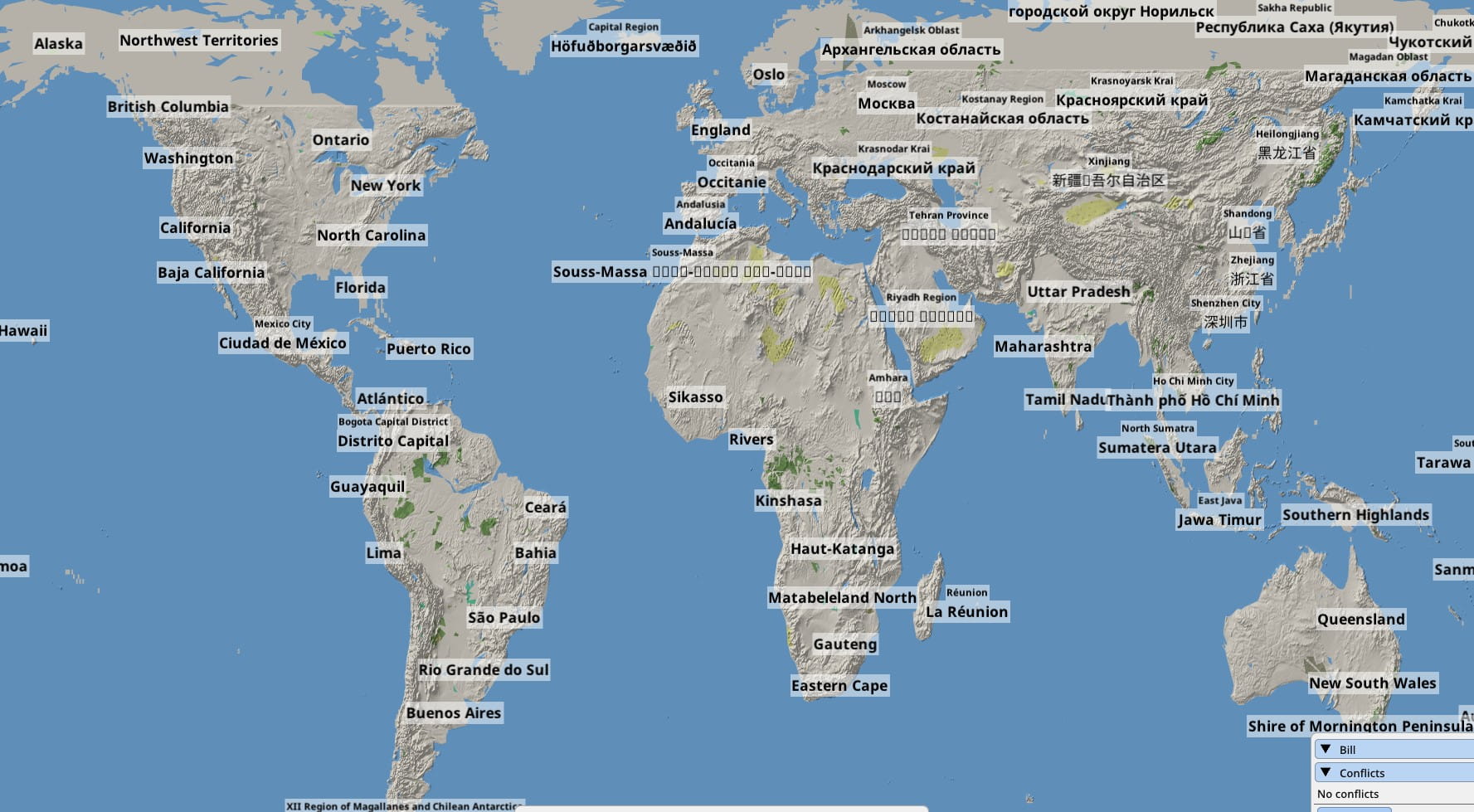
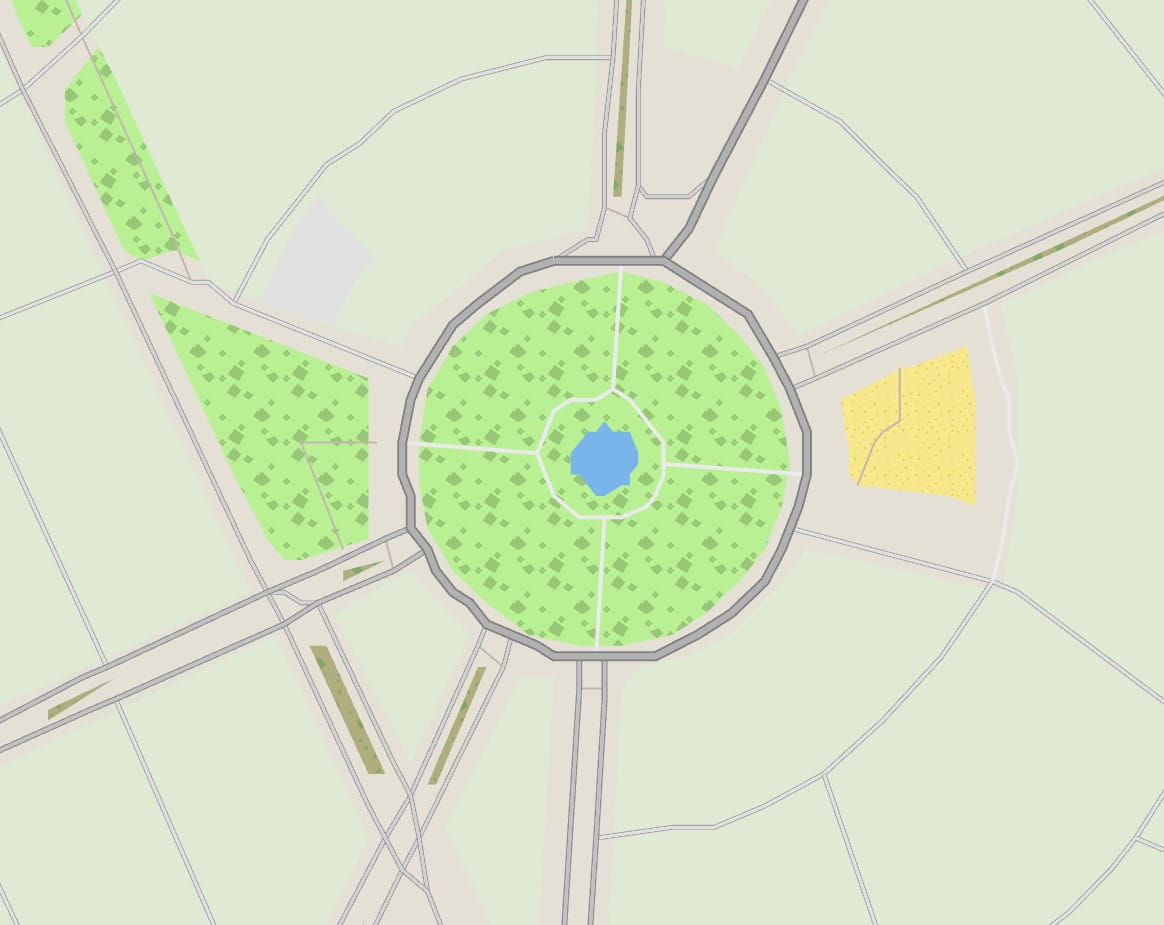
And with the land textures:
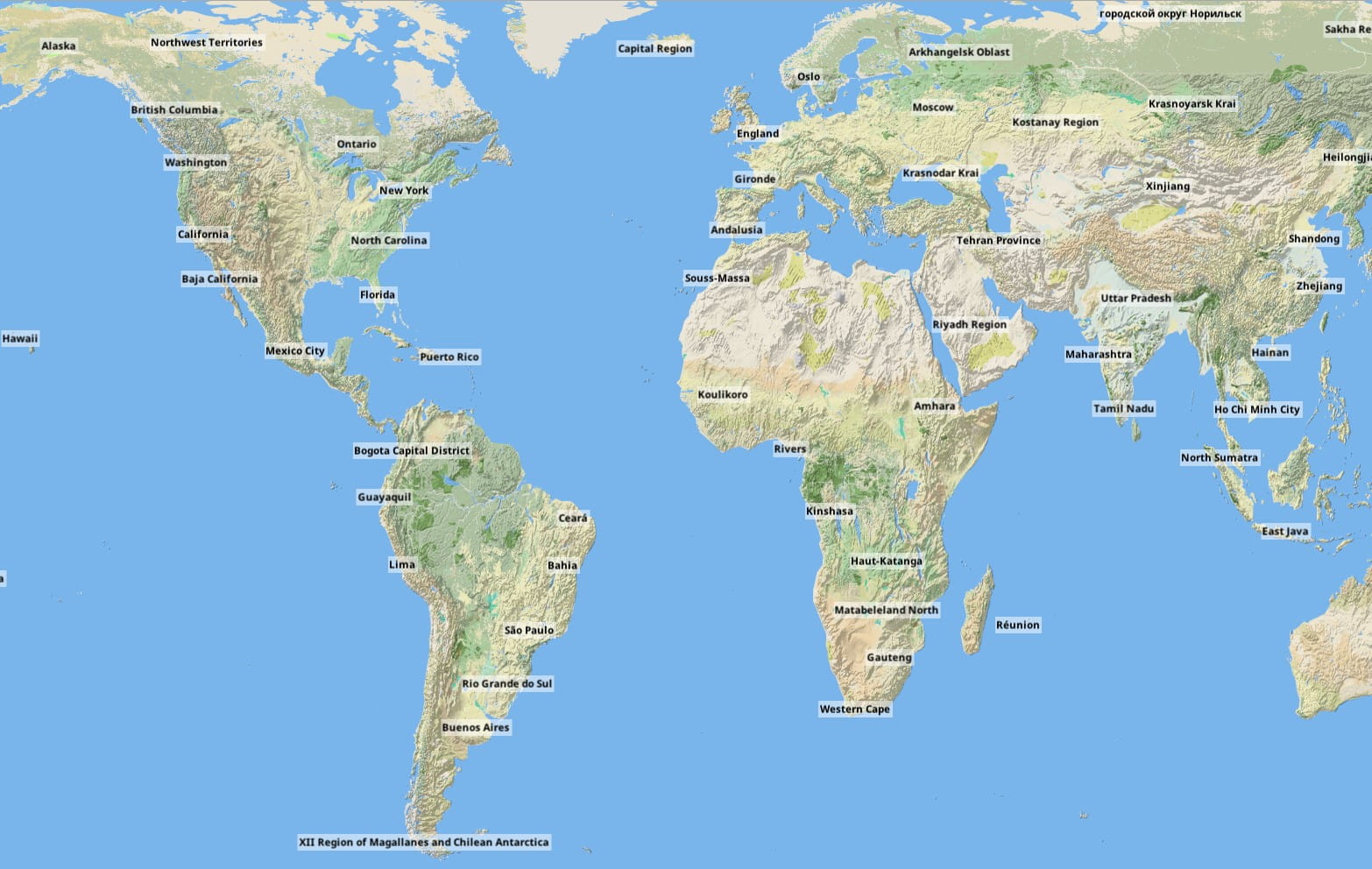
The combined improvement of these two new raster layers is dramatic for some areas at medium zoom:
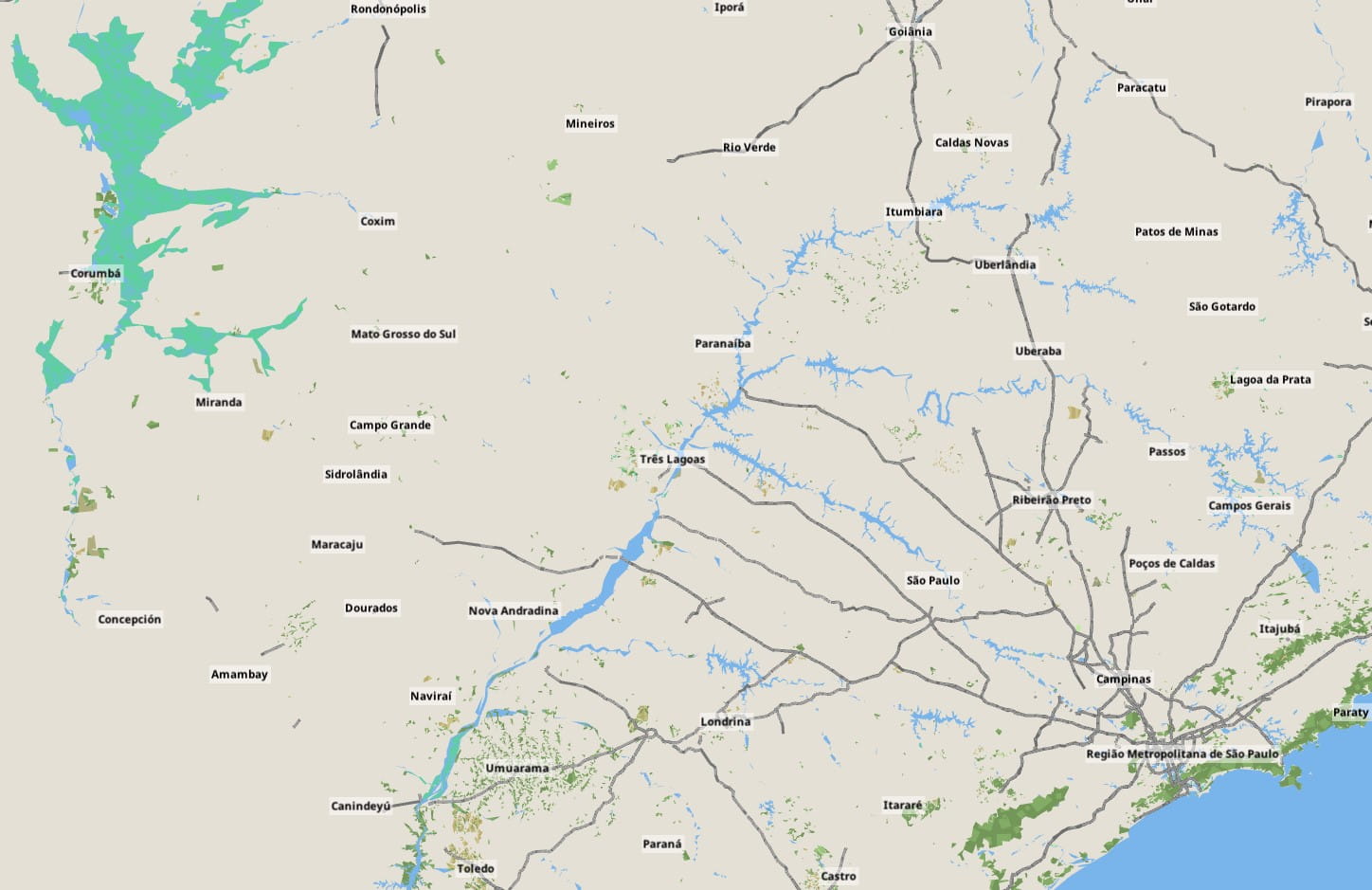
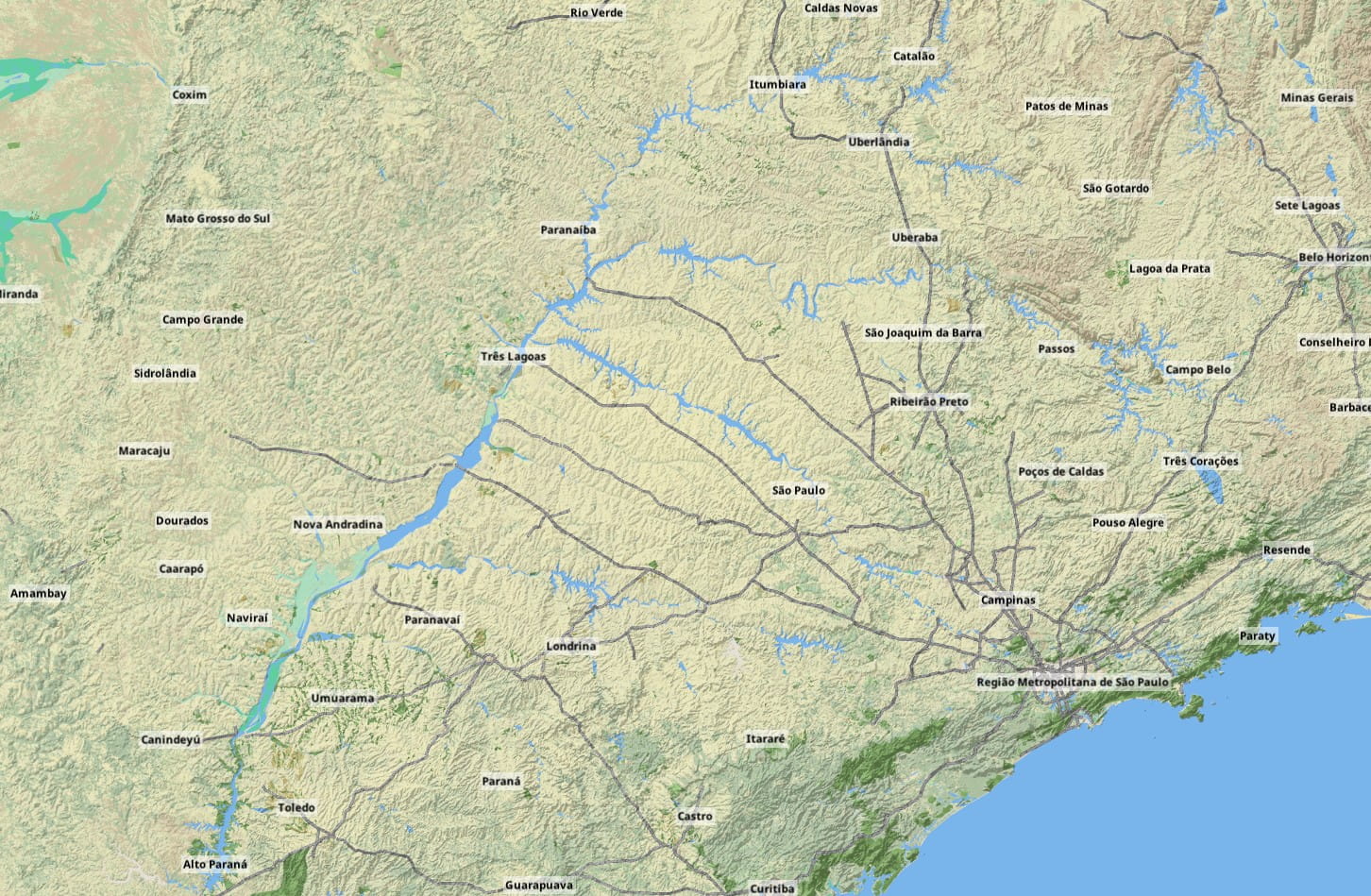
At the time I had already picked nuklear as the UI library for the game. I was at a point where the capabilities of the library were limiting me so I forked it and added 9-patch support to the skin system. But the main limitation was the lack of a sophisticated layout system capable of autosizing controls and windows. To this end I completely wrapped the subset of the nuklear API I was using with my own abstraction, and implemented a layout pass based on randrew/layout. I could now autosize every element of the UI with resolution independence, adapting to the available space and to the intrinsic sizes of elements like images and text labels.
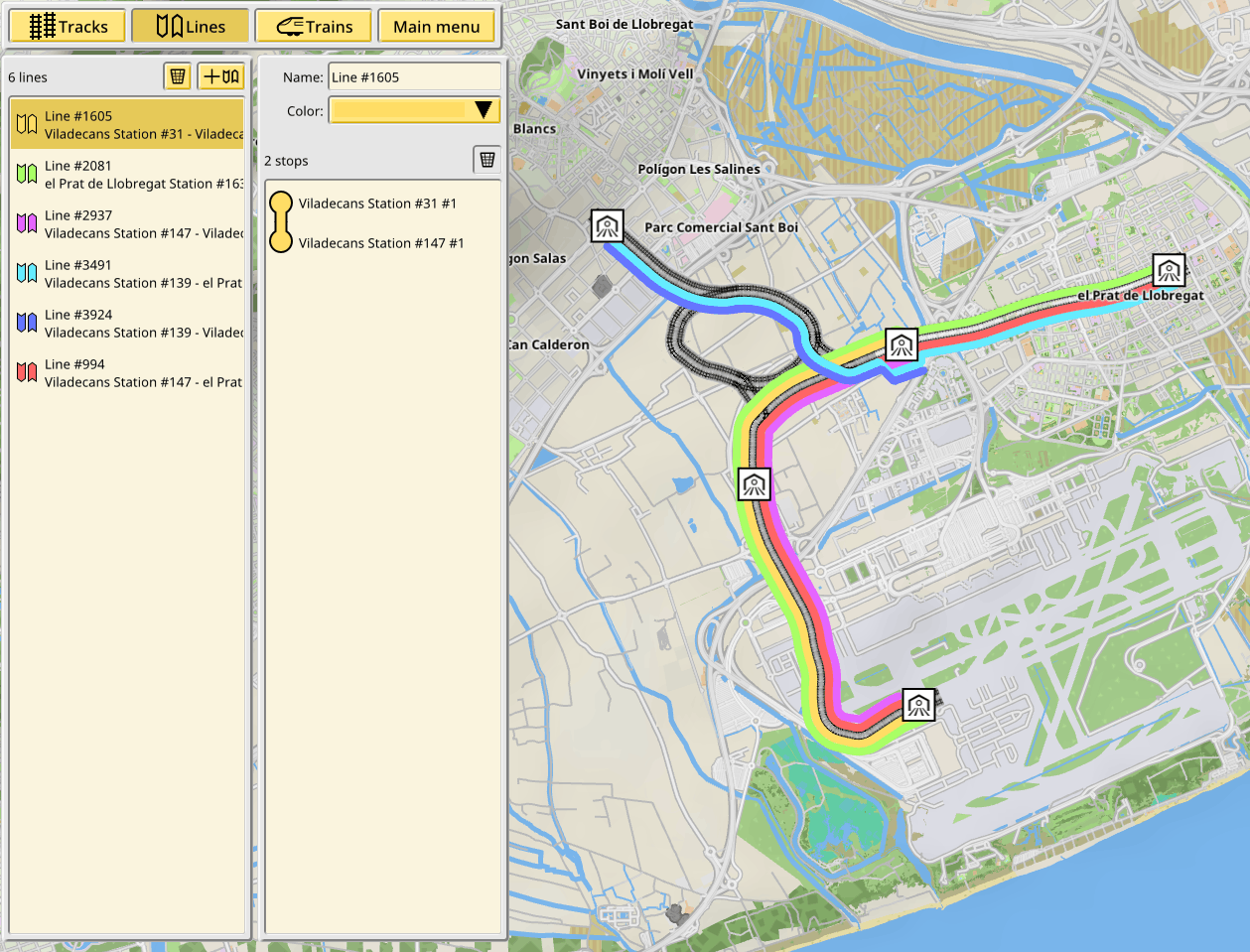
August 2019 — Lines
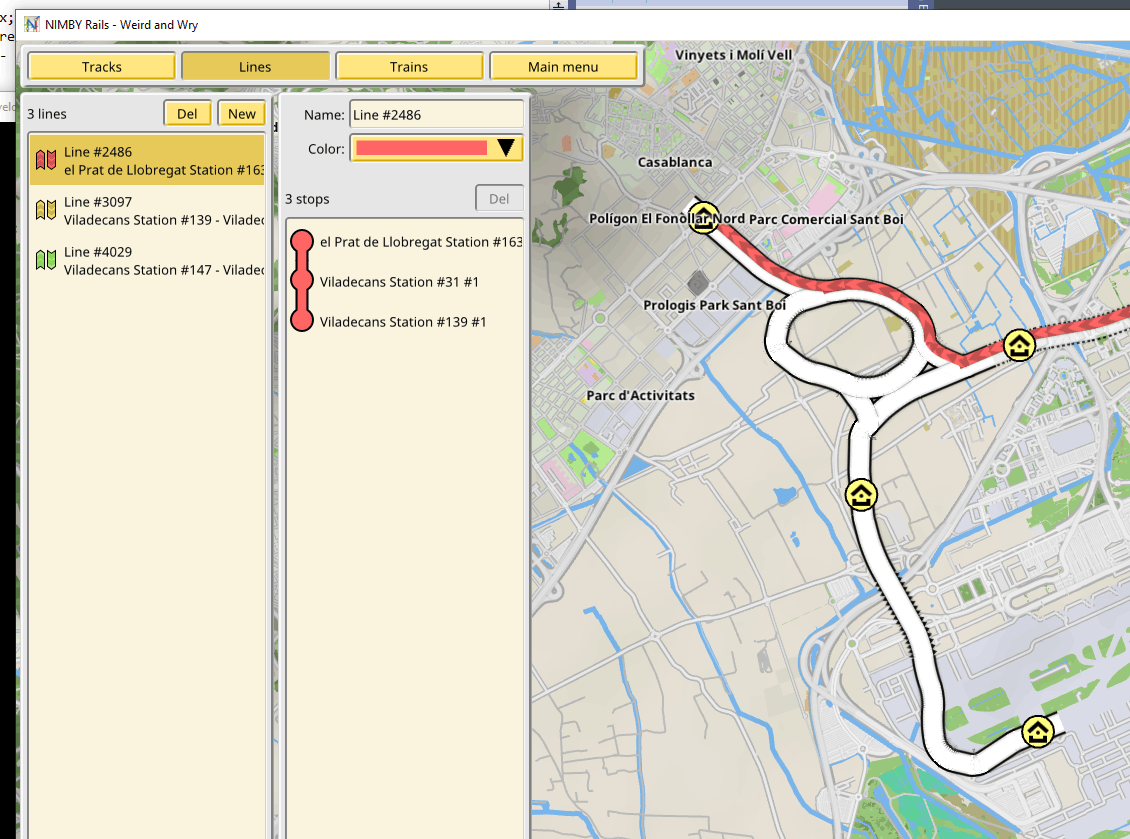
Lines are the concept of having a sequence of stations to be visited in order by scheduled trains. The scheduling part is not done yet, but the lines themselves are in.
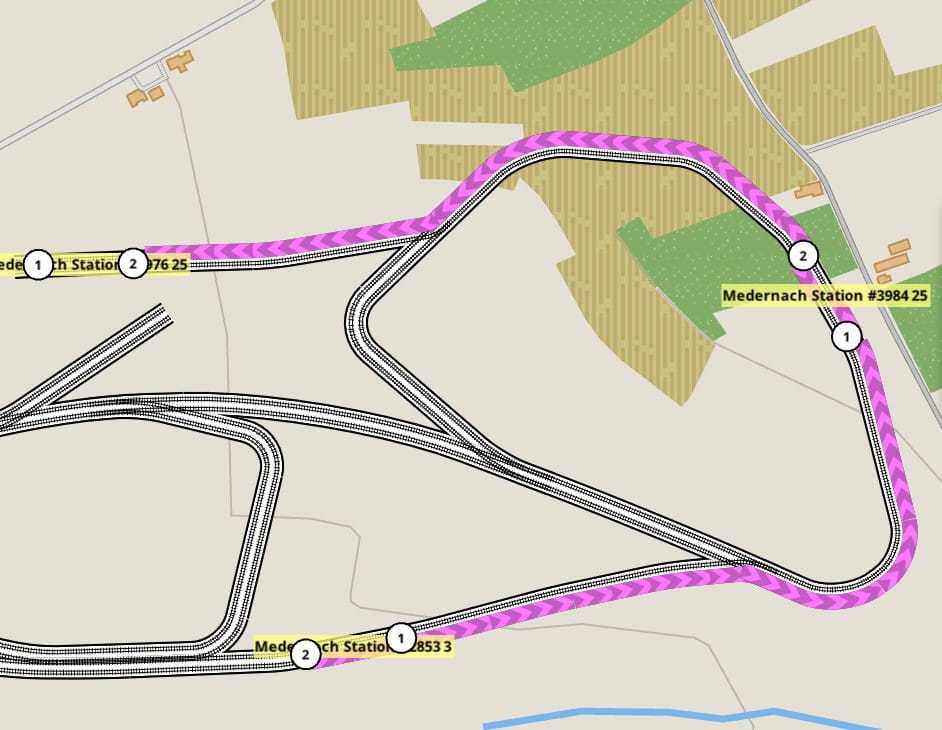
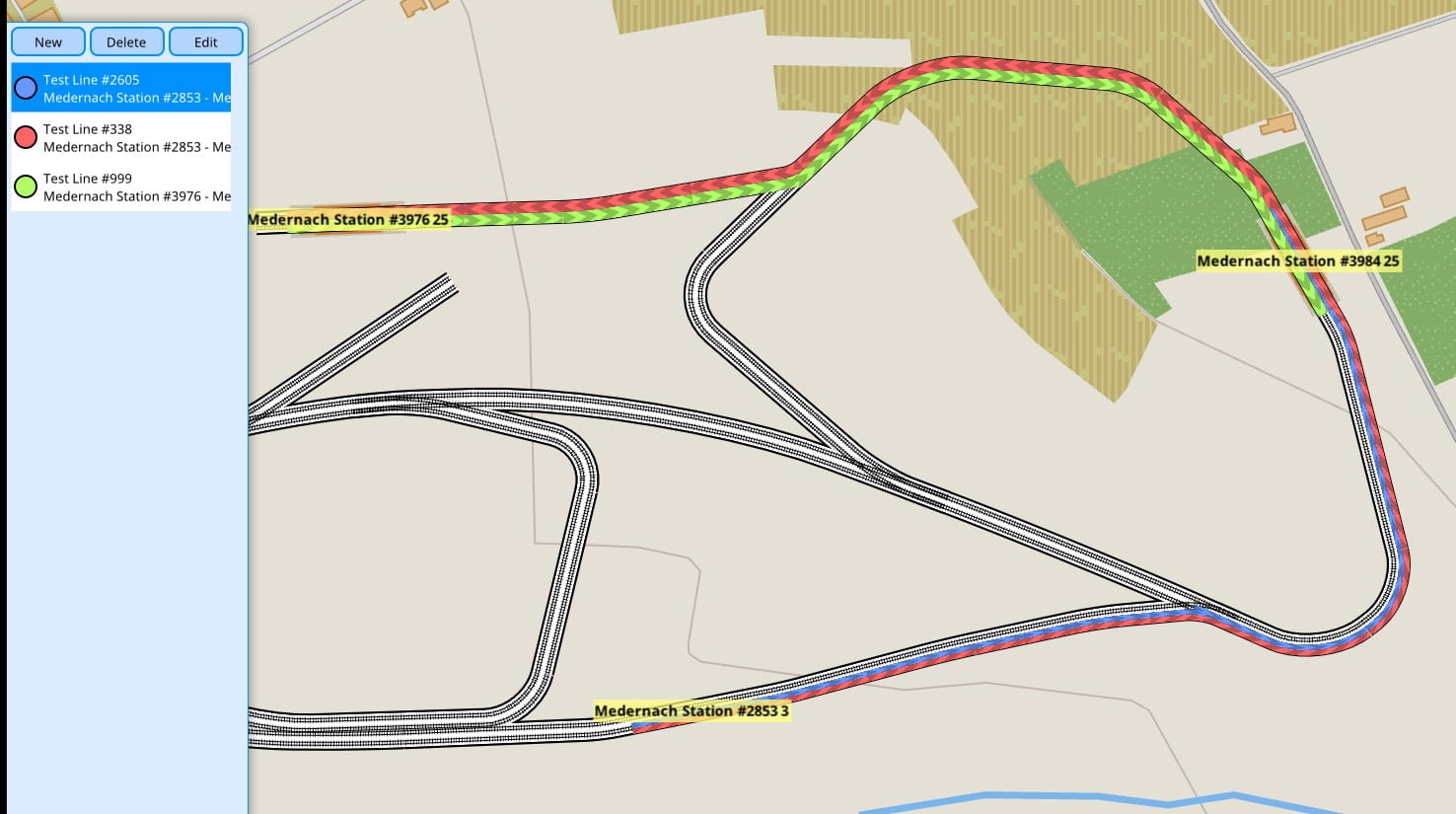
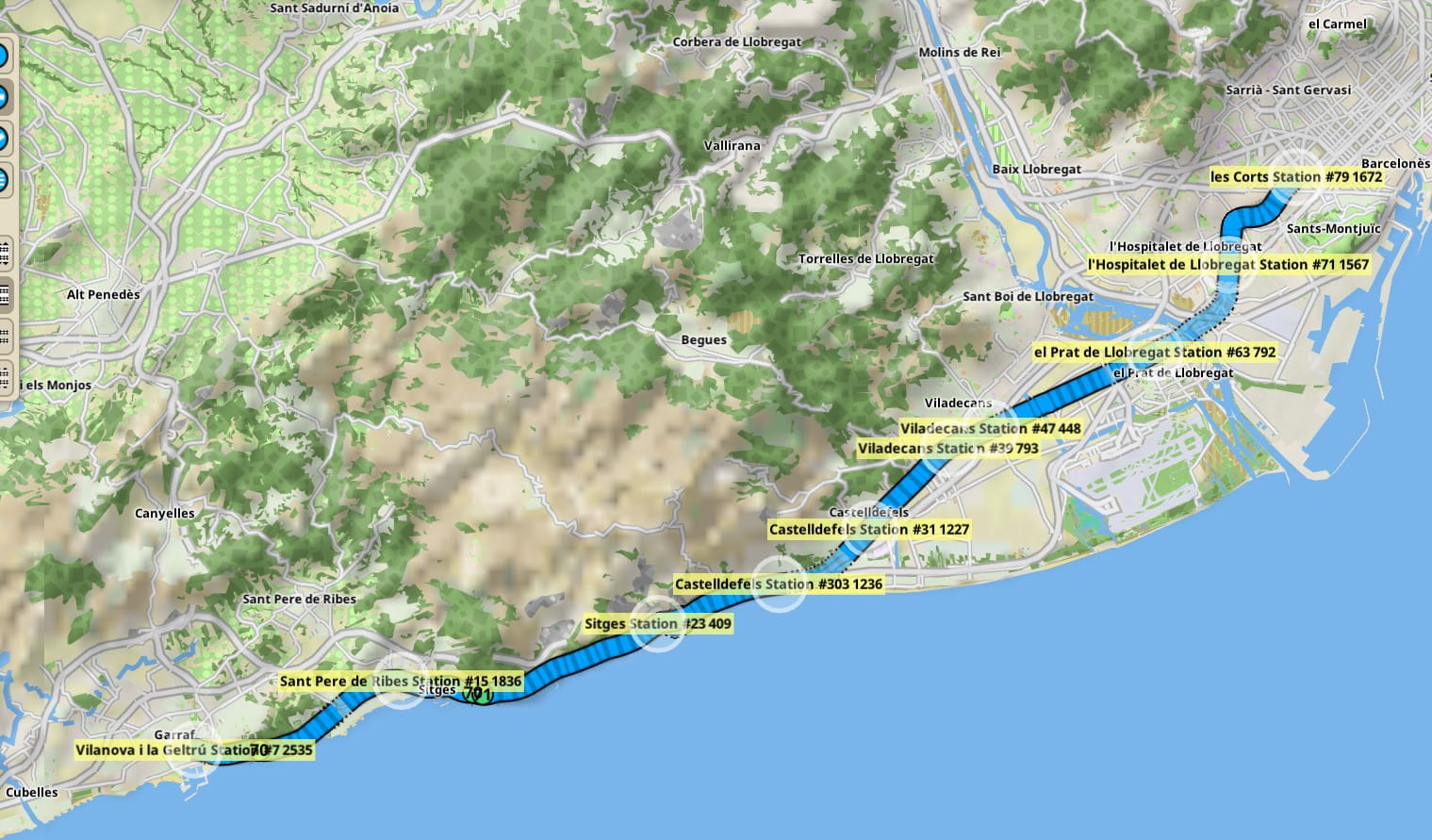
A lines editor with a visualization for them was added to the game. It is vital to make this aspect of the game as flexible as possible, so there are no limitations to the number of stations or their ordering. They also take into account the direction of travel. This aspect may be made more flexible in the future.
November 2019 — Visualization and UI improvements
I was now in the middle of the most difficult semester of my degree, but I still found the time to develop the game.

December 2019 — SVG based UI
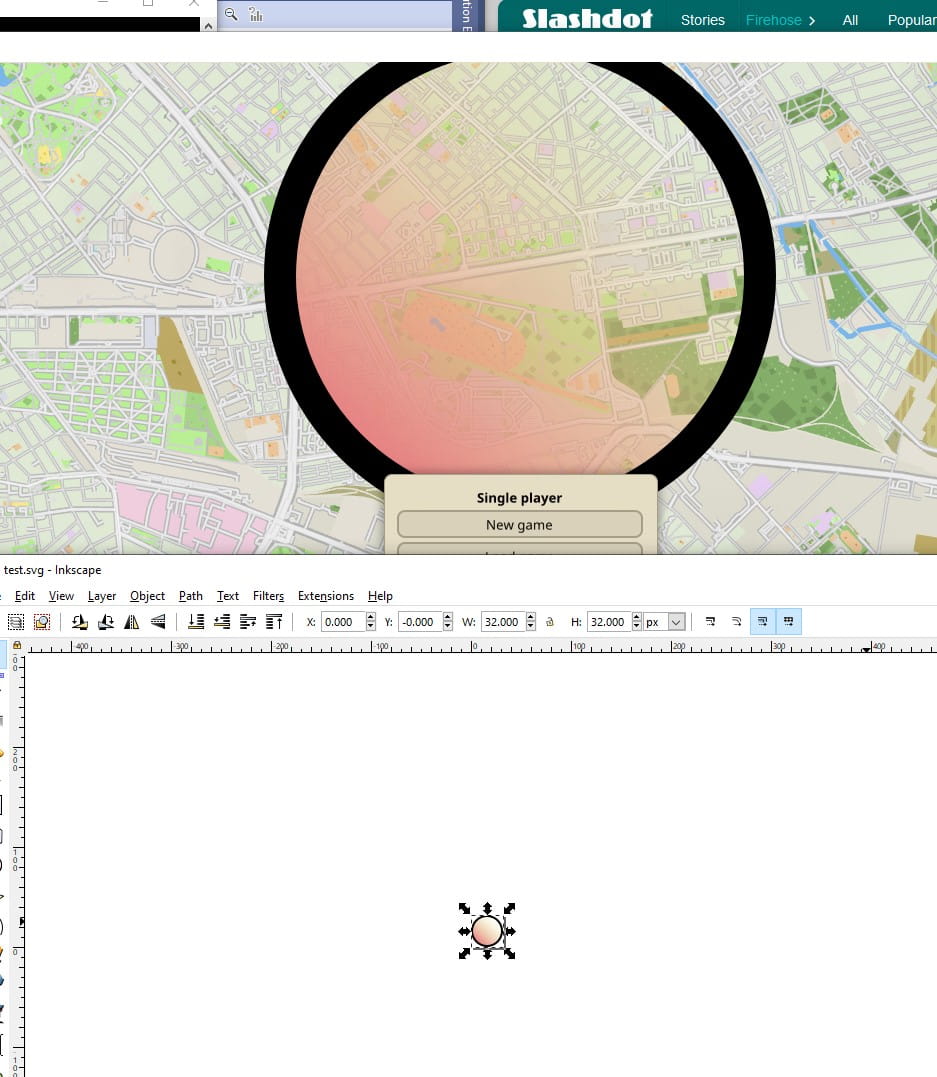
January 2020 — New vector UI skin, train editor
February 2020 — Polishing for the public reveal
The bézier based approximation for arcs is no more, and track tracing is now using real circle arcs. The result is virtually the same, with small radius curves being the most noticeable (but barely so). This was implemented by finding the intersection point of the lines that have the same direction as the normals at the start and end point of the arcs. That point is the circle center. Then the circle arc is traced using slerp.
March 2020 — Trailer and public reveal
I set myself the deadline of mid-March for the public reveal of the game. Most of late February and early March was devoted to the production of the game trailer.
Doing these large builds highlighted some flaws in the game. I fixed some of them as I went, and some others are scheduled for later. And after 18 months of working in secret, I was ready to show my game in Steam and start preparing for the future Early Access release.