NIMBY Rails devblog 2021-09
New map processing and format for vector data
If August saw the raster processing for the new map system, September was dedicated to vector data from OSM. Vector data is a lot less straightforward to handle. For starters it requires spatial indexing and an intermediate database, since the OSM PBF files are not suitable for geospatial queries. The new intermediate database is based on libmdbx. It stores OSM ways and relations in a soft compressed, soft serialized format, for quick retrieval without blowing up the database size too much. Nodes are always stored as coordinates directly in the ways, a new table in the future will also store stand alone nodes like POIs. Converting the OSM PBF file into this intermediate database is done with a new indexing process, much faster and efficient than before, and in a single pass over the PBF file. The required RAM is also drastically cut down compared to the original map processor (from 800GB to ~90GB). It’s now possible to run this process in a cheap second hand PowerEdge I got in eBay for 500 euros. Renting a 800GB RAM instance for the required processing time was more expensive than a physical second hand server!
As part of this new processing system a geospatial index is built directly on the MDBX database. This accomplished by directly storing the in-memory representation of a C++ port of flatbush. The internal access flatbush does to its data can be easily translated into read transactions, and it remains an efficient O(log N) lookup followed by a constant time cursor scan. The result is so fast and efficient it could be used as a general purpose GIS database with spatial indexing.
After the intermediate database is generated a new process creates (or appends to) an NRM file, the new custom map format for NIMBY Rails. This process takes some parameters, like a geographical region, a LOD range, and a filter specification, and creates a tile table for storing into the NRM. These tiles contain the vector information to draw the in-game map. Just like the v1 processor, ways and relations are pre-generated into triangles, and linear ways are preserved and serialized in an efficient way. The logic for this process is similar to v1, but some bugs have been fixed, and it’s simpler and faster. Extensive compression, quantization and delta coding is used everywhere. For now this system is limited to the new admin. region support in v1.3, but in the future all the game map data will re-processed with this new system.
Administrative regions
Admin. regions will be the first user of the new vector NRM tiles. In v1.3 NIMBY Rails will provide a new map layer to display the limits of some administrative divisions, from the equivalent of a “province” down to units smaller than a “borough”. I quote these names since the exact definition depends on the country. In OSM terms the game will include the data for admin. regions from level 6 to level 11.
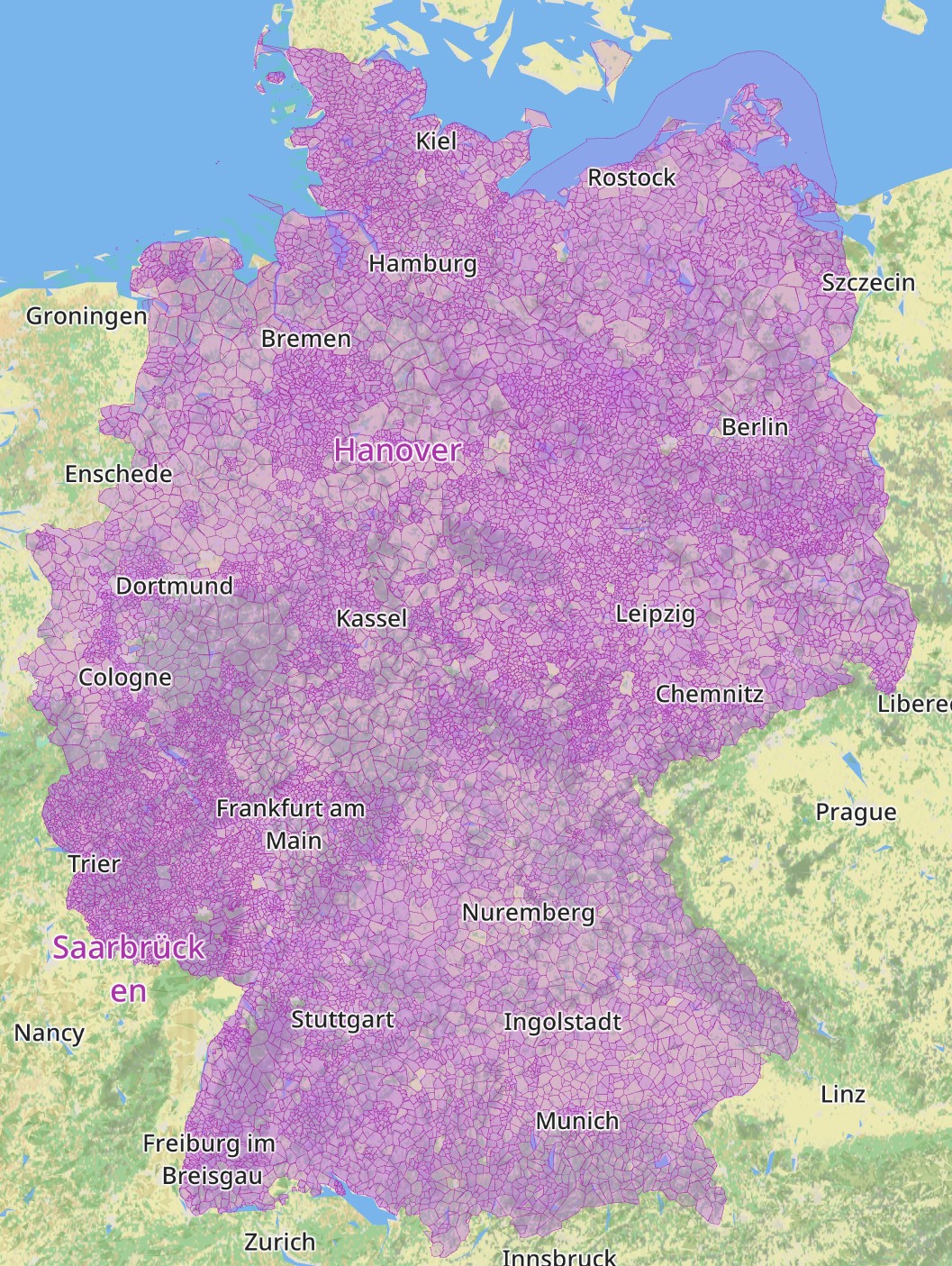
As always, map data in NIMBY Rails is not just an image, it’s also usable data. In the case of regions this data will be used to properly locate the “city” of player built stations. Again a variety of OSM levels will be considered, prioritizing level 8 and trying other smaller and larger ones that might make sense if the station does not fall inside a level 8 region. This will be just a display detail at this point, but it will become a more important gameplay element in the future.
Instanced line drawing
The drawing of lines (in the graphical sense: any linear feature displayed by the game, not just rail or schedule lines) has never been particularly efficient, but it was OK since initially most complexity was limited to the world map, and it was easy to find and test the max limit for it (Tokyo). But players have managed to build very complex networks, and in v1.2 every track got duplicated, duplicating also the required memory for displaying lines. This has translated into slowdowns in the v1.2 cycle and some corruption after hours of gameplay for some users.
v1.2 and earlier draw lines with a straightforward process: every vertex is duplicated and extruded following the normal of the line at that point, and a triangle strip is generated. All the strips are then stitched with degenerates and rendered with a single draw call.

The main problem with this approach is the duplication of vertices (to stroke the width of the line) and the huge amount of repeated data in the form of all those redundant texture IDs and colors.
v1.3 introduces a new way of drawing lines: instanced line drawing. Lines are now chopped down into 10 vertex segments. These 10 vertices are bundled with a single copy of the required texture IDs and colors. Other data like the normal is not stored at all, and are instead calculated on the fly in the vertex shader.

All the chopped segments are inserted in a single buffer, and the hardware is told to render as many instances as chopped segments are in the buffer. Instances of what, if the geometry is actually in the instance buffer? Of a triangle strip that serves as a template for a 10 vertex line segment (actually 20, due to the two sides of a stroked line). This template contains information of which nodes to look up inside the instance data, and which is the side of the vertex. This massively cuts down the required memory to display lines, by around ~6x.
For now this system is only enabled for map data like roads or rivers, and the region limits. It will later be ported to rails and schedule lines.
WIP Tag model and editor
Large builds can have thousands of trains and stations, and hundreds of lines. In order to make managing player built objects easier, and to power future features like conditional signals, a tag and category system is being introduced in v1.3. Players will be able to create an hierarchy of tags, with intermediate tags acting both like a tag and a category. And then assign those tags and categories to player built objects.
Work started by porting the existing train model tag system to the new design. Train models are already tagged and those tags have categories, so it was natural to try this first. A basic tag/category editor has also been introduced, although there’s not much to look at for now.
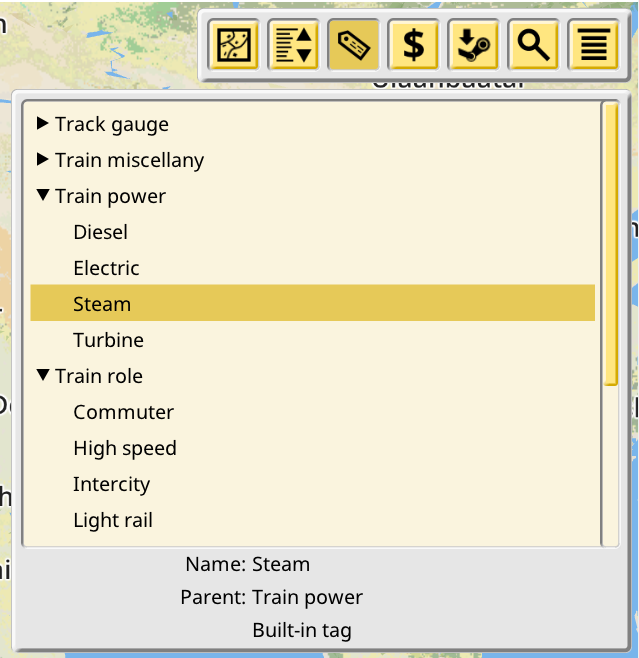
This editor will evolve into allowing users to create their own tags and nest them into whatever hierarchy they desire, and then the various objects editors, like the Lines panel, will allow users to assign tags to them. Then a new listing filter will be implemented to show these objects arranged and nested by their tag assignations, following the category hierarchy specified by the user.