NIMBY Rails devblog 2020-04
Internal development notes, very slightly cleaned up and commented a month later.
TL;DR: undo stack, working on pixel perfect high DPI UI, full rewrite of the internal game database.
NOTE: This post is even more technical than usual, there’s been few user-visible changes in the past month.
Undo stack

Having undo in the track editor has been for more than a year in my task list, and now it’s finally done. This has been enabled by the work on the new game state database, which makes it very easy to snapshot and efficiently store the changed state by an edit operation over the game state. It is a stack, so there is more than one level of undo.
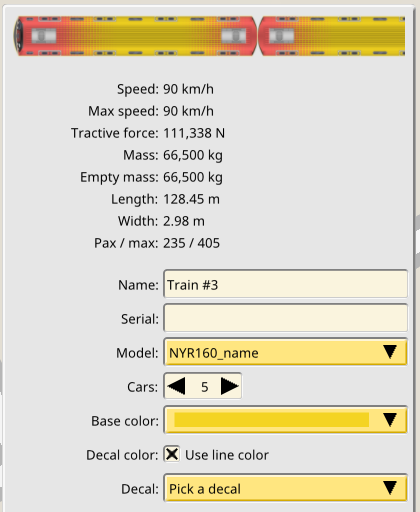
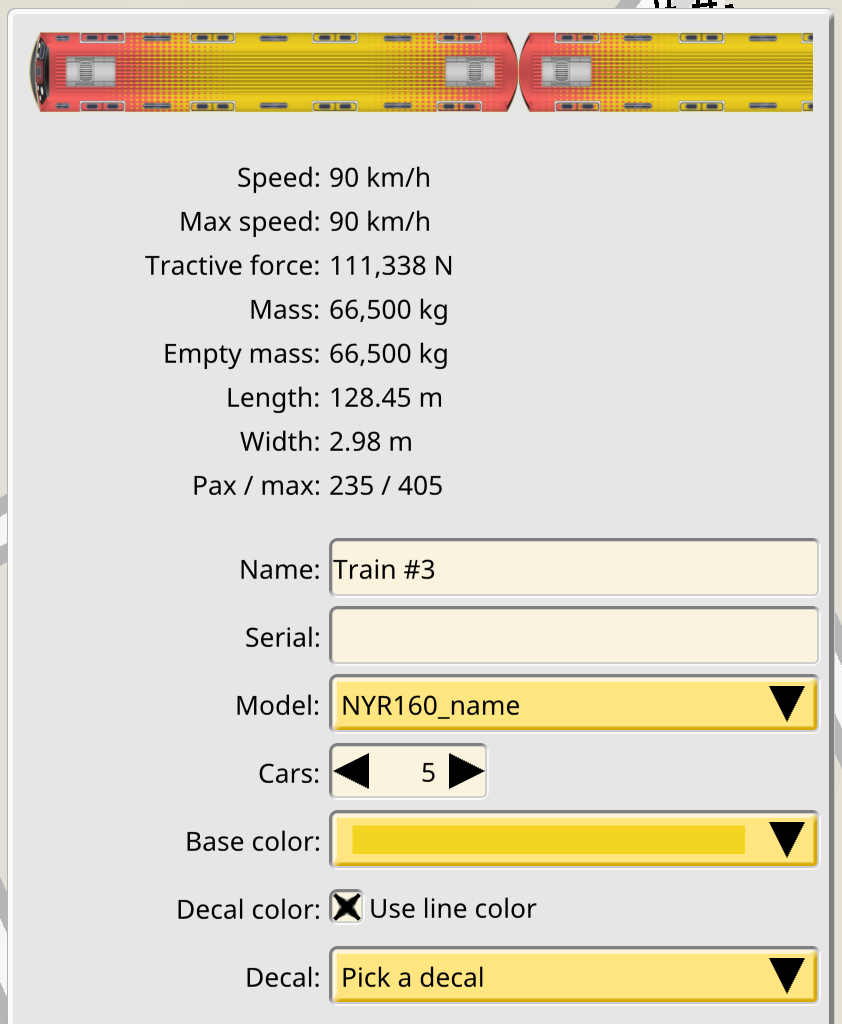
Pixel perfect UI controls and windows on high DPI displays
The game already supported high DPI displays in some areas, but the UI controls were unfinished. In addition to the existing SVG skins, spacings and alignment issues were fixed, to have a pixel perfect rendition of the same UI at every pixel density, including fractional ones.
This is 1x:
And 2x (right click -> View image):
Full rewrite of the game state container code
To achieve the lofty goal of multiplayer, in the way I want to implement it, the internal game state representation has to be practically bomb proof. Meaning, it must be able to be imported, exported, merged, validated, (un)serialized, over any sequence of the previous operations, for any possible subset of the game state. And all of this while maintaining a consistent data representation (and for operations that can potentially fail, like merge/import on multiplayer, a way to rollback and discard changes that does not nuke the entire state).
Since I’m never going to be hired again anyway, I decided to implement my own in-game database, supporting the subset of things I need. Internally I call this new database “model v3”.
model v1
The first data representation of the in-game state was as simple as possible in order to prototype faster.
struct State {
eastl::map<int64_t, Track> tracks;
eastl::map<int64_t, Lines> lines;
eastl::map<int64_t, Trains> trains;
};
You get the idea. This will get you very far just by virtue of highlighting the fact that the game state, the stuff you want to put in save games, synchronize over a network, or mutate in a simulation, is a distinct thing by its whole self. In my opinion it’s definately a bad idea to try to model your game state using typical OOP patterns if any of the previous goals are in sight. It’s doable (I’ve done it in The Spatials V2), but a real pain once you try to go beyond the basic visitor pattern or need to maintain serialization code all over the place.
Discarded idea for model v2
In The Spatials: Galactology I adopted an Entity Component System. Although I focused on the wrong aspects of it, it worked nicely, and made possible to support massive amounts of very distinct entities with common systems, something that ECS excels at. When trying to adapt the idea to NIMBY Rails I quickly discarded it. The dynamism support of ECS would only apply to trains, which are going to be quite monolithic simulation-wise and don’t really need the flexibility of the CS part of ECS.
model v2
I keep referring to some future multiplayer implementation, but the fact is that the game already had one. Based on the very simple model v1 I implemented a multiplayer collaborative mode for the track editor, and it worked very well. It had support for partial updates, which implied the code mutating the state had to be careful about logging every mutation it did. It also introduced the concept of import and validation, to merge serialized changes into a states and be able to validate them before merging.
From that ad-hoc implementation I arrived to a new design which looked like this:
template <typename T>
struct Store {
uint64_t serial;
eastl::map<int64_t, T> objs;
eastl::set<int64_t> deletions;
struct Changeset {
eastl::vector<T> changed;
eastl::set<int64_t> deleted;
};
void validate(Changeset const& changes) const;
void import(Changeset const& changes);
Changeset export() const;
void log_creation(int64_t id);
void log_deletion(int64_t id);
void log_modification(int64_t id);
// plus the internal log implementation
};
struct State {
Store<Track> tracks;
Store<Lines> lines;
Store<Trains> trains;
}
Now the game simulation and data rules code was able to log every operation it made to the state, and the Store code was able to generate Changesets based on these log operations. Serializing a Changeset would allow send game state changes over the network, for example.
I was on the right track, but this wasn’t enough. In particular it was easy to introduce very hard to track bugs when missing a log call, for example. I wanted to make the logging process as transparent as possible. Another new goal was to be able to layer data on top of data: instead of always importing a Changeset on top of a Store, be able to layer a Layer on top of an immutable Store. The Layer will accumulate all the changes and at the same time act like a normal Store to external callers. Oh, and of course, a Layer can be layered on top of another Layer.
model v3: it’s turtles all the way down.
So I basically ended implementing a log structured storage, transactional, in-memory database. The top level APIs look like this, with many details omitted:
template <typename T>
class View {
// ...
public:
virtual view_ptr<T> create(int64_t id) = 0;
virtual view_ptr<T> import(T const* obj) = 0;
virtual view_ptr<T> import(T&& obj) = 0;
virtual bool exists(int64_t id) const = 0;
virtual view_ptr<T const> view(int64_t id) const = 0;
virtual view_ptr<T> mut(int64_t id) = 0;
virtual void remove(int64_t id) = 0;
virtual bool merge(Changeset<T> const& changes);
};
template <typename T>
class Store : public View<T> {
db_pool<T> objs;
// ...
// own implementation of View methods
}
template <typename T>
class Layer : public View<T> {
Store<T> modified;
View<T> const& immutable_base;
// ...
// own implementation of View methods
// ...
// exclusive of Layer
Changeset<T> changes() const;
}
They key to make this idea performant is in the implementation of its smart pointer type, view_ptr, and of its two accessor methods, view() and mut().
view_ptr makes it automatic to promote immutable, base copies of an object into mutated copies. It stores a pointer to an intermediate object, a view proxy, that in turns points to what is considered the current, valid copy of an object. When the Layer that proxy belongs to decides to mutate an object, it also changes its view proxy (if any existed) to point to the new instance. The cost of view_ptr is then just the cost of a pointer to a pointer, rather than something more expensive, like a lookup table. A lot of effort was poured into making this true.
view() and mut() are the only ways for the model code to access its database. view() returns a read only copy. In the case of layer, if such an object hasn’t been mutated yet, a new proxy will be created and made to point what its base layer thinks it’s its valid copy. mut() first copies such a base object, then changes the proxy to point to the new mutable copy.
Two ancillary but very important pieces were also introduced: a transactionally-strong evolution of the Changeset idea and a generic type-indexed tuple container.
template <typename T>
struct Changeset {
// state of objects as it existed before the changeset
db_map<int64_t, T> pre;
// state of objects (old and new) as it existed after the changeset
db_map<int64_t, T> post;
// created objects inside the changeset that are still alive after the changeset
// they must not exist in pre, must exist in post
db_set<int64_t> creations;
// deleted objects inside the changeset that were still alive before the changeset
// they must exist in pre, must not exist in post
db_set<int64_t> deletions;
// ...
}
Changeset now stores more information about the data. In particular it gains the notion of recording object creation, and more importantly, its object store is divided into recording the state of objects as they were both before and after the changes. This simple design, coupled with strong rules on how to record objects and changes into a Changeset, has proven very solid. Changeset is now also able to merge other changesets into itself, in addition to serving as the data container for the Store and Layer merge() methods, and for Layer changes().
But what has become of State? And also, if consistency is desired, having separate Changeset per type doesn’t sound very reliable. So I introduced the concept of a std::tuple that is indexed by the types of its contents, helped by the amazing Metal library, which has changed my mind about heavy template metaprogramming.
// the usual C++11 tuple
std::tuple<Track, Line> t;
t.get<0>(); // access the Track field
// my monstrosity
type_tuple<Track, Line> t;
t.get<Track>(); // access the Track field
It, obviously, requires distinct types in every position. I didn’t stop there tho. Instead of expressing a State snapshot as:
type_tuple<Changeset<Track>, Changeset<Line>> t;
I introduced another type indexed tuple, that does automatic “application” of a type over the field types:
type_apply_tuple<Changeset, Track, Line> t;
static_assert(std::is_same<Changeset<Track>, decltype(t.get<Track>())>{});
This type also provides generic map() (with a different application type for the output if desired) and each(). I can now add any amount of object types to the model State and not have to special case, or enumerate fields in different spots to visit them all.