NIMBY Rails devblog 2023-04
Track + point pathfinder
The new track pathfinder is now implemented in 1.8. As a recap, this new pathfinder is capable of finding paths when given an start and goal represented by points in a track, rather than using pairs of consecutive tracks as start and goals (the internal steps of the path still are, and always have been, capable of being represented as a track and point).
All systems have been migrated to the new pathfinder, and the old one has been deleted from the code. Along the way some adaptations have been made to keep existing saves and UI usable. For example, even though the new pathfinder could mark any point in any track as a station stop, the line UI is still based on the familiar arrows, and station platforms still exist and and still are based on pairs of tracks. You can use platform stop signals to set this stopping point, like in any other version.
A new capability which can be added without disruption is in-place flipping. The new pathfinder understands the concept of not just one, but two points of start and two points of goal, representing the front and the back of the train. If the pathfinder caller knows the train starts and/or ends the path at 0 speed (so, a stop rather than a waypoint), it can tell the pathfinder to consider the tail of the train as a valid start or goal point. Paths are then found with this knowledge, and the found path can actually represent a goal for the train back rather than the front, for example. In-place flipping is a prerequisite for later supporting proper push-pull operation, or even to support flip-less trains which require an actual track loop for reversal.
Tracing and riding paths as a core game object
A path from track point A to point B is just a sequence of tracks, which needs to be interpreted in order to extract the exact ranges and positions on the tracks. This is called “tracing” the path. The pathfinder was the common core, but different systems built their own way of tracing a path. The first one to exist, and the most complex, was the train AI. From the simple instructions stored in the pathfound path, the train AI extracted distances, signals, speeds, reservations, line stops, collisions. But as the game grew more complex, other systems also required the capability of tracing paths. Signals themselves also require finding a path (common code), but then trace the path with their own code, different from the train AI. More problematic was the line leg calculator, which not only was content with the features of the track, it also tried to simulate a train with its physics but without running the train AI.
As time passed all of these path tracers were unified into two: the train AI and “the other path tracer” which powered everything else. They were very similar but not fully identical, and the more was built on top of them, the more they diverged. The train AI worked by “consuming” time, and the other path tracer worked by “consuming” distance. So you can tell the train AI “given this train with this path, tell me where it is in 1s”. And the path tracer, “given this path at this point, tell me where it leads me if I advance 100 meters”.
In 1.8 this situation does not exist anymore. Along with the new pathfinder, I developed a new, two level path tracer, which powers everything, including the train AI.
The first level is the most similar to “the other path tracer”, a geometrical-like path tracer which knows nothing about train physics and it’s useful for things like signal checks and reservations. You feed it a path and a current position, and ask it to move the position forward X meters. But most crucially, it’s not a separate piece of code anymore. It is in fact the basis for the new tracing layer, the path rider.
New in 1.8 is the path rider. This layer on top of the path tracer simulates the train physics. It replaces thousands of lines of code from the train AI. You also give it a path and a current position, but also a current speed, and ask it about where the position is going to be in X seconds, and at what speed. The path rider is not tied to train AI in any way, and it can be reused in other parts of the code, like the line leg simulator, for very precise time estimations. It focuses on doing one thing and doing it very well, and other events in the track, like collisions or signals, are delegated to upper layers, if these layers decide to require them.
Profiling performance with Tracy
Like with any major rewrite of core game systems I was worried about performance. I was also aware that some of the previous efforts at parallelization were not fully working. So I finally decided to properly instrument my code and start using a frame profiler. I picked Tracy, which is exactly what I needed, a parallel frame profiler.
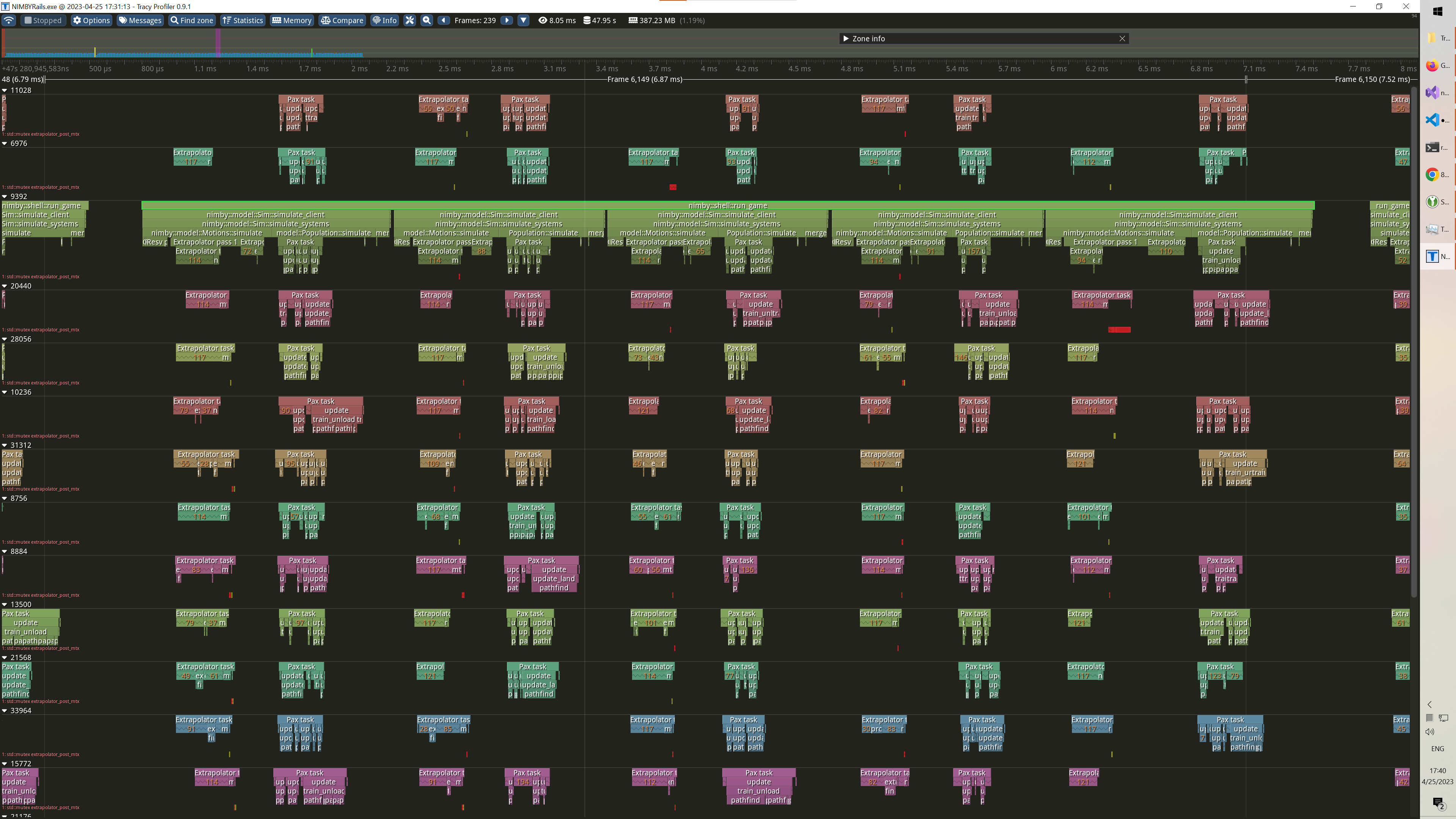
In this image shell::run_game represents all the time devoted to running game logic for a given graphical frame. It manages to run five simulation frames within a graphical frame of around 6 milliseconds (with 600 trains and 70K+ ridership; 1.8 is fast). Each simulation frame is Sim::simulate_systems, and it’s dominated by two main systems: Motions::Simulate (train AI) and Population::Simulate (pax AI). All of these calls happen in the simulation main thread, but once you drill down into them, you can see parallel tasks spilling all over the available threads in the machine (20, not all of them fit in the screenshot). Extrapolator are tasks running one or more train AI, and Pax task are tasks running all the pax related AI for one or more stations (spawn, train unload and load). As you can see, the game simulation is already massively parallel, but there are still areas with zero parallelism. After all Extrapolator are run, some trains still remain to be processed. These are trains which cannot be processed in parallel: signal waiters (or passers-by), and spawning trains. And pax also has a final step, merge, which merges accounting data, that cannot run in parallel.
Thanks to Tracy I could time the new pathfinder vs the old one, and realized it was essentially identical, so no performance regression was observed despite the new capabilities. But on the parallelism aspect, I discovered the train AI was spending a lot of time processing accounting. Like, 2/3 of the train AI time was just processing accounting (this is prior to the previous screenshot; the problem was already fixed when I took it). It didn’t matter how much effort I spent on optimizing train AI, it was just erased away by the accounting part. So I decided to take some drastic measures.
Asynchronous accounting
Accounting was slow for two reasons: new accounting data cannot be aggregated in parallel, and historical series are immediately updated when new accounting data arrives.
To fix both of these problems, 1.8 stops making any effort to have perfect up to date accounting data for every object in the game on every time series, with the exception of Company. Instead accounting data is aggregated in a temporary buffer for each object, and then, as time goes on, small chunks of this buffer are aggregated into the real accounting database, at a very slow rate (currently 1/30 of simulation frame rate). The consequence is that the accounting for trains, lines and stations now lags a bit compared to the simulation time. For example, if you run the simulation at 100x speed, train accounting data will be up to 3 seconds (game time) old at any given moment. I think this is acceptable. Also the temporary buffers are immediately flushed into the accounting database when some UI actions are triggered, like exporting accounting or saving the game, so no accounting data should be lost.
Slow down pax station flow
Now moving to Pax tasks, more analysis of Tracy data showed that it was generally very fast, thanks to past optimizations, but the current tunning of pax flow was making train unloading into huge processing spikes. 1000+ pax trains were unloading in a single simulation frame, which is kind of ridiculous. I decided to tone down pax flow quite a bit, since honestly it has been too fast for the last two versions and maybe it would be a cool idea to have pax flow as a gameplay element again at some point in the future, unlike the current situation of virtually all trains finishing their pax processing in a few seconds.
The other change in 1.8 is one which is kinda meh since it ignores flow, but I think it’s necessary. Flow tells the Pax task to process pax at a pax/s rate, but processing 10 pax going into 10 different destinations is absolutely nothing like processing 10 pax going into 1 destination. The real processing limit is in the variety of destinations, not on the pax number. For this reason train unloading is now throttling the amount of different destinations processed per frame per train to just 5. This forces train unloading to be broken up into several frames, without having to radically decrease pax flow. I will tweak this during the 1.8 beta if it’s too slow.
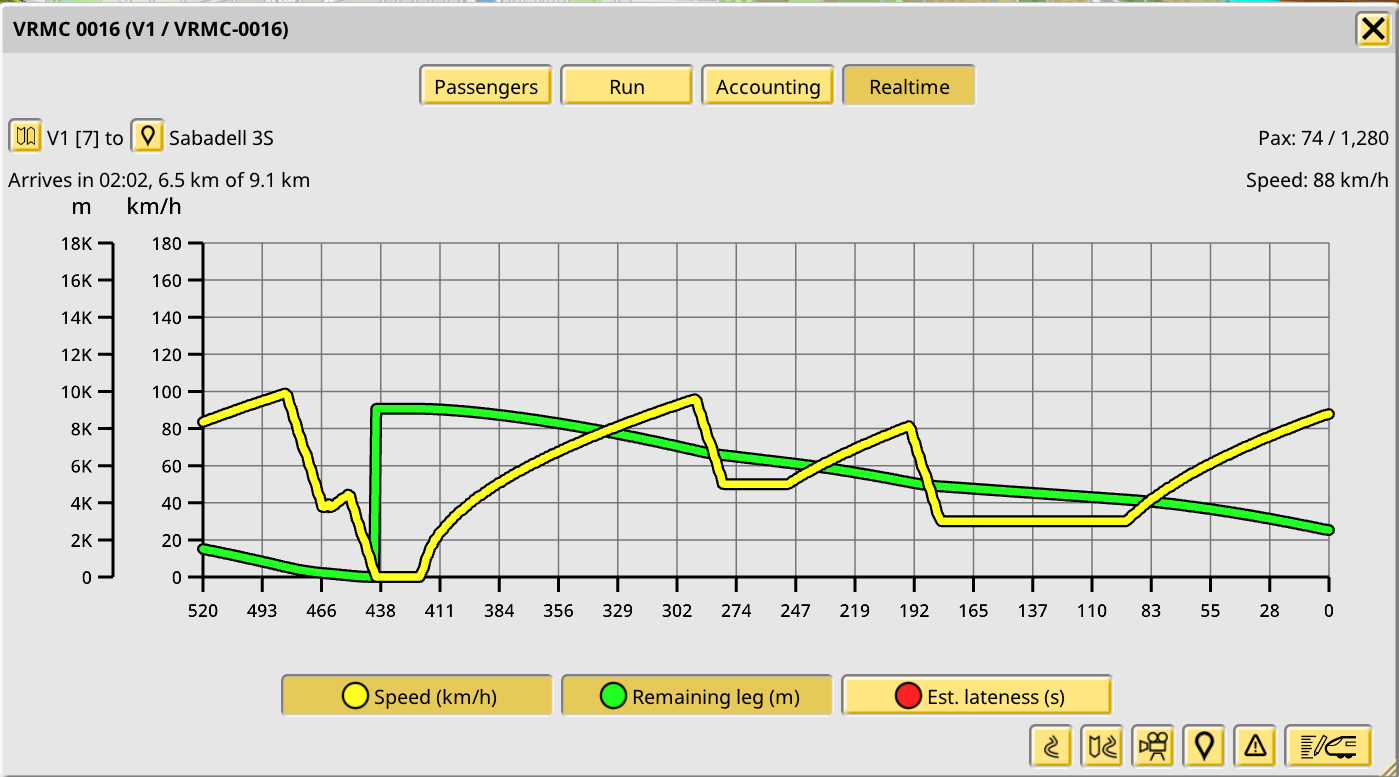
Realtime plot tab in train window
For the next tasks I needed some visualization of the train speed over time, so I added it to the train window, plus a couple extras:
Acceleration and traction limits for cars
Train cars (and thus, trains) can now declare acceleration and tractive effort limits. Both max acceleration and regular brake acceleration can be specified, and a value for a future (unused for now) emergency brake is also possible. Additionally an optional max tractive effort value can be provided. This also has the effect of limiting train acceleration, but does so proportionally to the mass of the train, which is more realistic.
Improved braking and sane line timing
As mentioned earlier, there is now an explicit braking acceleration value to use by the train AI. But rather than handle braking at the train level, it is handled at the path rider level. This means all users of the path rider automatically handle braking like a train would. Braking into a line stop itself has also been improved. Previously it was just an action undertaken by the train AI at the moment its path into a line stop ended, as part of the next line leg. This situation was unsustainable and the attempted fix in 1.7 didn’t help much.
Now in 1.8 a line leg (which is just a path) really only ends when the train reaches the end point of the leg, and this happens when the braking halts the train. This means a stop arrival is the moment a train reaches 0 speed, a stop departure is the moment the train starts from 0 speed, and leg is just the difference of the two. No more separate braking time or split time between two legs.
Braking itself has also improved. It now starts at the correct braking distance for a given future stop, even if said stop is still a dozen path steps (or tracks, or km) away. The line leg timer handles this exactly the same way the train AI would, because now the path riding code is the same for both.
Path-adaptive braking
Real braking was looking very cool, but it was still true it only applied to halting on reaching the path goal. But while riding a path, a train can find other path steps which force it to change its speed, like track speed limits. And ideally these should also involve braking, rather than a sudden change of speed.
I was initially discarding this for the future, equating it to the dynamic speed braking required for things like signals or not rear ending other trains. But it’s also true track speed limits are static, and easy enough to know in advance as part of the already stored path. So I set upon analyzing the problem and finding a performant way for the path rider to anticipate speed changes, and in the end I found a technique to make it possible without tanking performance:
The naive way is just looking up all future steps in the path and note down the points at which a new max speed limit is in effect (if the goal is a stop, it is also a max speed limit, with a value of 0):

The key enabler of this idea is the fact braking acceleration is a constant. This means it is possible to come up with a max speed approach function for every max speed change, as a function of the distance to the speed change point. This function tells the train “if you are at X distance from this speed change, your speed cannot exceed Y”:

So in the example image, the train in the left evaluates the all the functions between its position and the goal. The result of each evaluation is a max speed, and then it takes the minimum as its max speed (and the max train speed, and its current track max speed, and its line service speed if not late). This automatically produces a linear deceleration as if the train was deliberately braking.
This worked very well, but I found unacceptable for the train to have to look ahead an indeterminate number of steps to check these speed limiting functions. Indeed this is a quadratic cost in the worst case, when considering the full set of steps the train will make to reach the goal. Two first obvious optimizations are clear: keep a counter of the steps behind the train; these will never be considered again, and the train can skip them. And never consider any future step a distance beyond what it would take the train to brake down to a halt considering its current speed. These two greatly reduce the amount of steps the train considers, but there was still another interesting optimization to make, which even allows to cut down the amount of steps stored (speed change steps are stored separately from path steps, since they don’t have to map 1:1):

The functions with a vertical red line are “dominated” by a future function. This means limiting the train speed by them has no effect, since a future function is more strict than them for their entire range of values. So they can be removed from the data, and the train will still slow down at the right moments:

These optimizations make this system have virtually zero impact in the performance of the path rider, and they also set the foundations for future improvements to the concept of evaluating paths. Information about dynamic signaling could also be included in the future to make it possible for the train to evaluate them in advance, introducing concepts like sight distance for example.