NIMBY Rails devblog 2023-11
Stop and continue
After 1.10 was finalized in October, I analyzed what remains to do in the roadmap, plus what are the outstanding issues in the game, in order to decide what to do in 1.11. What is clear is that the remaining roadmap items will have an outsized impact in game performance. It cannot be assumed that, for example, the game will suddenly allow pax to pick routes based on multiple criteria like price or services, or that signals will suddenly be able to force stops based on priorities, with zero performance impact. Additionally, it’s a bit strange to be thinking about these kinds of features while undo can still be a bit of meme and multiplayer has scaling issues at with middle and large saves (multiplayer will never match singleplayer in scaling capability, but the ceiling should be higher).
“Unfortunately” I’ve already extensively optimized the game in every release so far, so there’s very little in the core algorithms to cut and improve. And undo and multiplayer have already been touched and retouched many times, specially in the case of multiplayer.
So I decided to devote November to work on a very major refactoring of the core of the game, to first try to extract more performance with a different strategy, and second to seize the opportunity wrought by the changes required by that optimization to also try to partially reimplement undo and multiplayer.
Fully independent, asynchronous UI and game logic
The game simulation logic is very multithreaded, but it also needs to paused. Some of these pauses are internal, but the major pause is because the UI needs to read its data and render it on screen. These UI pauses fully stop the game sim from running, and they are longer the more complex the UI render becomes. So the more tracks and trains on screen, the slower the game runs, not just because of the rendering, but also because there’s less time for the simulation to run. This is very clear when running the game with Tracy instrumentation:
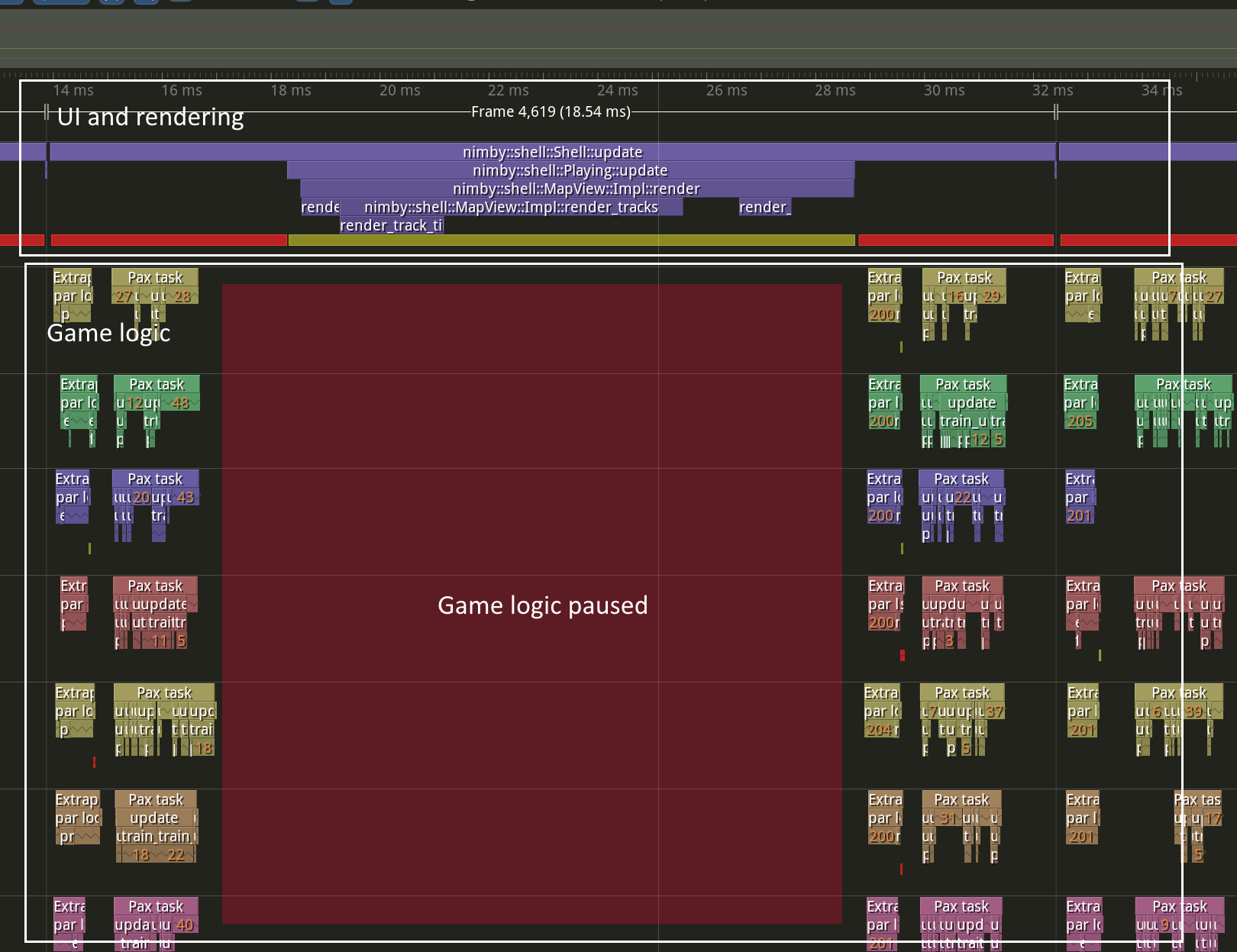
In the screenshot, each row represents a thread. The top thread is running the UI, and all the others are devoted to the game logic (this is on a 20 thread CPU, there’s more than in the screenshot). The game sim is deeply multithreaded. It has some internal pauses, but they are dwarfed by the massive pause it has to take while the UI is rendering.
In 1.11 this picture changes, and as of this writing it looks like this:

Now the game logic threads are running without waiting for the UI to catch up. They just loop infinitely until a lifecycle event like saving or quitting tells them to pause or stop. They still have internal pauses, but these are much shorter. This has been accomplished by introducing two new, very major changes to the game architecture: transactional database changes and triple buffered sim state.
Transactional database changes
Allowing the UI and logic to run in parallel is all about controlling the flow of data. And there’s 2 flows: the UI wanting to change the data due to user actions, like using the editors. And the UI wanting to display the data, like drawing tracks and trains.
Transactional database changes are about the first flow: the user editing game objects. Up until 1.10 this was trivially accomplished since the game sim was stopped. The UI editors directly called into the logic methods for creating, modifying and deleting objects. But if the sim is running, these actions would crash the game, since now the sim is reading from a database which is changing under its nose without any kind of coordination.
What I call the “database” is the collections of objects the user can control. These are track segments, lines, orders, and the non-simulation part of trains. This is separate from the simulation state, which is the pax and something called the “motions” of the trains, things like the current train path and its position on the tracks.
In 1.11, when the UI wants to change the database, it cannot do so directly. Instead a command system has been introduced, which is very much like transactions in a stand alone database would be. They consist of a small amount of data and code,they run in isolation of all other commands, and they have write access to the database. The UI queues one or more of these commands in a queue, and they are run in an asynchronous fashion at some point in the future. These queued commands are then executed between sim executions, and run fast since they are just one or a few logic methods, rather than being interspersed with large amounts of UI code.
Despite being part of a performance optimization, this change also helps the track editor undo. In 1.10 and earlier undo worked in a very contrived way. It basically simulated the same methods the multiplayer system uses for keeping player local changes on top of server changes while these have not been synchronized. Doing that required things like re-applying the changes twice, which is what happens in multiplayer (once by the user in their PC, and a second time when the server OKs them). With the command system this is not required anymore. The code which changes things in the database is already neatly isolated in the context of a command. Now when these commands are run it is possible to register the precise changes they make and record them away on a single try, without having to reapply them. This has made undo more robust, but it also surfaced fundamental bugs in how some track editor tools worked. It turned out some tools depended on this “do it twice” behavior. These have also been fixed.
Triple buffered sim state
As important as the command system is, and as complex it has been to implement (10K lines of code modified…), it’s actually the smaller part of making the UI and sim parallel. The big part is the other flow, the UI reading database and simulation data to render the game.
To make it possible for the UI to render data in parallel, that data must not change while the UI is rendering. The usual strategy is to keep more than one copy of the data: while one part of the code modifies one copy, the other part reads from the other copy. In particular the most flexible way is to keep three copies: the working buffer, an intermediate buffer where the working buffer is copied, and the rendering buffer, which gets (atomically) swapped with the intermediate before rendering.
From the start it was clear this was not going to be possible for database data. In large saves (100K+ tracks, 1K+ trains) the database can be 100MB+ large after you add all the auxiliary data required to work with it, like geo indexes and caches. But it’s not really required to keep copies of the database. The database, unlike the simulation, only changes when the player issues a command. Compared to the sim it is almost immutable, plus now it had a coordinated command system to not affect the sim. I decided to only keep one copy of the database.
But for some of the simulation data making a copy is tractable. For example train motion data is about 1MB per 1K trains. Copying 1MB can be done very fast in today CPUs. So I arrived at a design:
- The database will remain a single copy, using the command system and shared locking when the user makes a change
- Very hot, but simple enough sim data, like train motions and simplified station pax numbers, will be collected and copied on every sim frame, for every object
- Heavy sim data like the full pax detail required to render train and station info windows, or accounting, will be only copied on demand, and possibly at less than 1:1 UI frame rate
No new features or gameplay changes in November, maybe in December
I’m currently halfway in the implementation of the triple buffer system. It already works for the hot sim data like train motions, but there’s still a lot of pending work to restore other UIs like the train and station info windows. There’s also more opportunities for improving the parallelism. In the second screenshot I highlighted some red areas. These are also pauses in the sim. They are shorter than the massive UI pause but they add up to a lot of wasted time, and I want to make them as short as possible.
The game is in a good spot and I’m in no rush to start new roadmap projects, so I will take as much time as needed in December to finish this optimization effort. These roadmap features depend on extracting as much performance as possible. Players loading 1.11 to find the game runs 5x slower won’t care if pax now take fare price into account when they kindly report their constructive feedback, so this work needs to go first.